In this study, data of patients with breast cancer were retrieved from the SEER database and served as example data. The SEER database provides data on cancer representing around 34.6% of the United States population, and permission to access the database was obtained (reference number 12296-Nov2018).
Two nomograms (Figure 1), both including histological type, differentiated grade, T stage, and N stage, were established using the direct method and the weighted method, respectively. The points of each level of variables and the probabilities corresponding to the total points were almost the same, while some slight differences were observed. Zhang et al. introduced a "weighted" approach to establish a competing risk nomogram, which first transformed the original data to weighted data (using function crprep), then constructed a Cox regression model with the weighted data (using function coxph), and finally established a competing risk nomogram with the Cox regression model (using function nomogram)9. In contrast, the "direct" approach in this study is totally different from the "weighted" one. In short, the parameters generated from the competing risk model (using function crr) replaced the parameters in the Cox regression model (using function coxph), which was finally used to establish the competing risk nomogram (using function nomogram). In the comparison of the nomograms established by the "weighted" method and the "direct" method, the two nomograms were similar in general, while some slight differences could be observed. The "direct" method in the study is more precise because it obtains the parameters for constructing the nomogram directly (with the formula "score=log(log((1-real.3y),(1-cif.min36)))/(maxbeta/100)" in section 2).
In rcorr.cens(X, Surv), X is a numeric predictor with cumulative incidences at any time point, and Surv is a survival object containing survival months and status. When Surv defines patients experiencing competing events as censored and then generates a life table, the evaluable ordered pair is identical. The C-index of the competing risk model without validation was 0.7978 (95% CI = 0.7650-0.8305), indicating this model had moderate discrimination ability. Bootstrap analysis was repeated 500 times, and the 500 results were then averaged to produce a single estimation for calculating the C-index. The C-index in the internal validation was 0.7978 (95% CI = 0.7651-0.8305), which was similar to the C-index in the original dataset. An external dataset was fitted into the competing risk model, and the C-index in the external validation was 0.5071 (95% CI = 0.4637-0.5505). The AUC of the competing risk model was calculated from the original dataset in the study. The 36th month AUC was 0.8461 (95% CI = 0.8232-0.8691), demonstrating the discrimination ability of the model.
As shown in Figure 2A, points on the calibration curve were close to the equivalence line, and the 95% CI of the observed frequency fell into the equivalence line in each group, indicating the accurate calibration ability of the model. Calibration curves using internal and external validation are shown in Figure 2B and Figure 2C, respectively, indicating that the constructed model had a good calibration ability in the internal validation but a poor one in the external validation.
As shown in Supplementary Figure 1, the points representing the observed cumulative incidences distributed around the line representing the predicted cumulative incidences, and no significant differences were observed between the observed and predicted incidences. The results of the decision curve analysis are shown in Figure 3, which presents the changes in net benefit with increasing threshold probability.
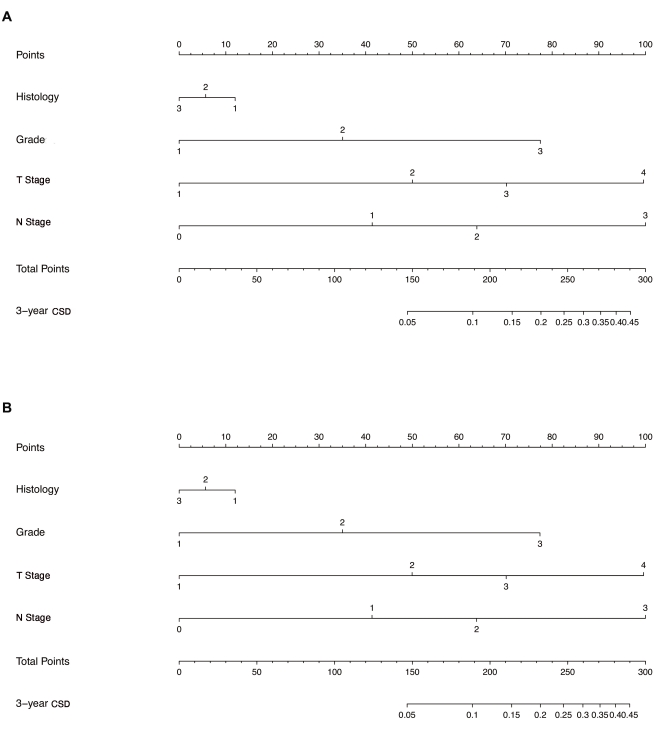
Figure 1: Establishment of the competing risk nomogram with two methods. (A) Nomogram established using the direct method. (B) Nomogram established using the weighted method. Histology: 1,invasive ductal carcinoma; 2, invasive lobular carcinoma; 3, invasive ductal carcinoma + invasive lobular carcinoma. Grade: 1, well-differentiated; 2, moderately differentiated; 3, poorly differentiated. T Stage: 1, T1 stage; 2, T2 stage; 3, T3 stage; 4, T4 stage. N Stage: 0, N0 stage; 1, N1 stage; 2, N2 stage; 3, N3 stage. Abbreviation: CSD = cancer-specific death. Please click here to view a larger version of this figure.
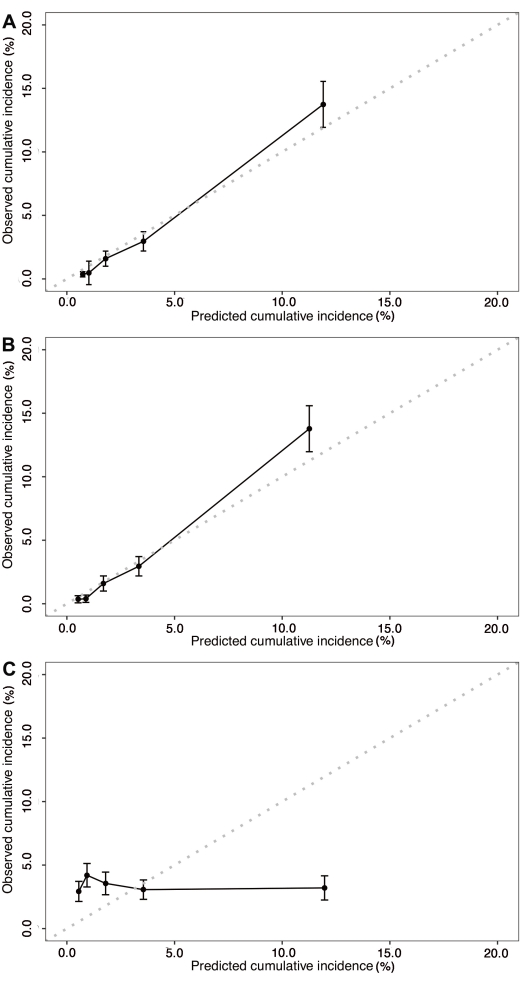
Figure 2: Calibration curves of the competing risk nomogram. (A) Calibration curve with a confidence interval of the established competing risk model. (B) Calibration curve of the competing risk model in the internal validation. (C) Calibration curve of the competing risk model in the external validation. Please click here to view a larger version of this figure.
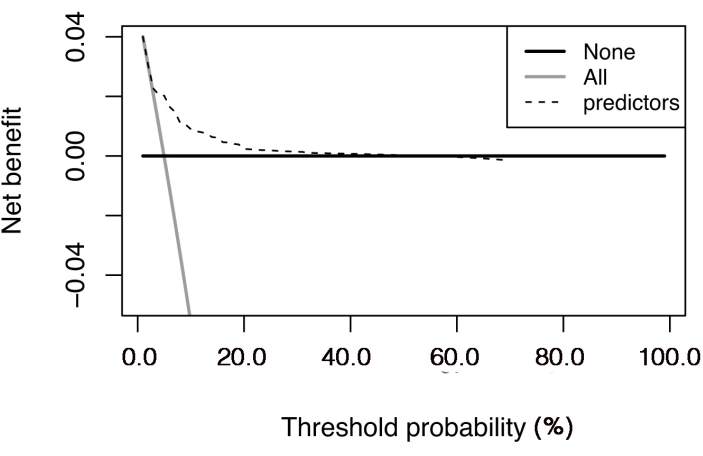
Figure 3: Decision curve analysis of the competing risk nomogram. The net benefit is plotted against the threshold probability. The "all" line shows the net benefit by considering all the patients that suffered cancer-specific death, and the "none" line is the net benefit by considering all the patients that did not suffer cancer-specific death. Please click here to view a larger version of this figure.
Supplementary File 1: Breast cancer data. Title definition: grademodify, differentiated grade; histology, histological type; stageT, tumor T stage; stageN, tumor N stage; Survivalmonths, the time from the date of treatment to the date of death due to any cause or censor; death, death (including cancer-specific death and non-cancer-specific death) or censor; death3, cancer-specific death, non-cancer-specific death, or censor. Please click here to download this File.
Supplementary Figure 1: Calibration curve with risk scores of the established competing risk model. The points representing the observed cumulative incidences were distributed around the line representing the predicted cumulative incidences. Please click here to download this File.
