Thirteen C. glabrata comprising C. glabrata ATCC 90030 and 12 isolates from the Clinical Mycology Reference laboratory (isolates CMRL1 to CMRL12), Westmead Hospital, Sydney were studied (Table 1). These included three pairs of isolates CMRL-1/CMRL-2, CMRL-3/CMRL-4 and CMRL-5/CMRL-6 obtained before and after antifungal therapy with no epidemiological links between them 24 (Table 1).
The MICs were determined using CLSI interpretative breakpoint for nine antifungal agents namely, Amphotericin (AMB), Anidulafungin (ANI), Micafungin (MIF), Caspofungin (CAS), 5-Flucytosine (5-FC), Posaconazole (POS), Voriconazole (VRC), Itraconazole (ITR) and Fluconazole (FLC). Candida parapsilosis ATCC 22019 and Candida krusei ATCC 6258 were used as quality control strains. Among the isolate pair, CMRL-1 and CMRL-2, the second isolate CMRL-2 was resistant to caspofungin (MIC 8 vs. 0.12 mg/L, Table 1). CMRL-2 also had similar proportional increases in the MICs of anidulafungin and micafungin (≥ 0.5 mg/L) resulting in in vitro resistance to all three echinocandins24. Likewise, isolate CMRL-4 had developed echinocandin resistance than those of isolate CMRL-3 (Table 1). Between the third pair, isolate CMRL-6 had a 5-flucytosine MIC (>64 vs. 0.06 mg/L)24. Both these isolate pairs were susceptible/wild-type (WT) to other antifungal agents tested. Isolate CMRL-6 and CMRL-12 were found to be resistant or non-WT to all azoles. CMRL-7 was resistant to fluconazole and non-WT to voriconazole (Table 1). C. glabrata ATCC 90030 and isolates CMRL-8 to CMRL-11 were susceptible susceptible/WT to all antifungal agents24.
WGS of 13 isolates was performed using the benchtop sequencer. On an average, a mid-output sequencing run, yielded around 27-40 GB data with an error rate between 0.5-1.4%. The average percentage Q30 obtained was usually around 80-85%. The flow-cell cluster density (K/mm2) ranged between 200-250 (Table 4). The raw sequence data from this study have been deposited at NCBI Sequence Read Archive (SRA) under the project number PRJNA310057. 98% of sequencing reads mapped to the C. glabrata reference genome (strain CBS138) through analysis in integrated data analysis software. The average read depth coverage was 75x with average read length of 143-bp. Structural variant detection identified more than 50, 000 SNPs per isolate. Particularly, when analyzing the strain pairs CMRL1/CMRL-2, total SNPs found on each isolate were around 79,000, for CMRL-3/CMRL-4, the total number of SNPs were around 60,000 and for CMRL-5/CMRL-6, more than 56,000 when compared to CBS13824. The SNP difference when compared between isolates in a strain pair was less than 25.
Based on the susceptibility profile of the isolates, known resistance biomarkers were selected for analysis24, particularly, FKS1, FKS2 and FKS3 (echinocandin resistance), FCY1 and FCY2 (5-flucytosine resistance), and ERG9, ERG11, CgCDR1, CgPDR1 and CgFLR1 (azole resistance). The genes were checked for known mutations, and frequency of SNP occurrences. Only non-synonymous SNPs in genes with read depth coverage of ≥20 i.e., high-quality SNPs (hq-SNPs) were specifically studied.
Notably, FKS mutations were identified in the genome of both echinocandin-resistant isolates24. Of the first two pairs, the echinocandin resistant isolates, CMRL-2 harbored a single FKS2 mutation S629P, and CMRL-4, the FKS2 mutation S663P (Table 6). Of the third pair, a SNP in FCY2 (Ala237Thr) was found in both CMRL-5 (5-flucytosine susceptible) and CMRL-6 (resistant) (Table 6). However, SNPs in FCY2 were also found in other phenotypically-WT isolates (CMRL-1, CMRL-2, CMRL-10)24. Isolates CMRL-6 and CMRL-12 were noteworthy for their pan-azole resistant/non-WT character and had SNPs in both CgCDR1 (encoding azole efflux pumps) and CgPDR1 (encoding the transcription factor regulating the efflux pumps) (Table 6)26,27. The presence of mutations in another efflux pump gene, CgFLR1 occurred in both azole-susceptible, and azole-resistant isolates26,28. Investigation for SNPs within the ERG9 (coding squalene synthase) revealed mutations but there were no mutations identified in ERG1124.
WGS analysis also revealed multiple non-synonymous SNPs in Candida cell wall adhesion genes namely, EPA1, EPA6, PWP2 and PWP5. EPA6 mutations were present in 9/12 isolates. SNPs in PWP2 and PWP5 were also present in almost all isolates, except isolates CMRL-1 and CMRL-1124.
| Isolate | AMB | ANI | MIF | CAS | 5-FC | POS | VRC | ITR | FLC | Interpretation of antifungal susceptibility | Genes Conferring Resistance Identified by WGS | ||
| CMRL-1 | 0.5 | 0.03 | < 0.008 | 0.12 | < 0.06 | 0.5 | 0.12 | 0.25 | 8 | Susceptible to all | – | ||
| CMRL-2 | 0.5 | 1 | 1 | 8 | < 0.06 | 0.25 | 0.06 | 0.12 | 4 | Resistant to all echinocandins only | FKS1 | ||
| CMRL-3 | 0.25 | 0.015 | 0.015 | 0.12 | < 0.06 | 1 | 0.25 | 0.5 | 8 | Susceptible to all | – | ||
| CMRL-4 | 2 | 1 | 1 | > 8 | < 0.06 | 0.5 | 0.12 | 0.25 | 8 | Resistant to all echinocandins only | FKS2 | ||
| CMRL-5 | 1 | 0.12 | 0.015 | 0.12 | < 0.06 | 1 | 0.5 | 0.5 | 16 | Susceptible to all | – | ||
| CMRL-6 | 1 | 0.06 | 0.015 | 0.06 | > 64 | > 8 | 8 | > 16 | 256 | Resistant to 5-FC and azoles | FCY2, CgPDR1, CgCDR1 | ||
| CMRL-7 | 0.25 | 0.06 | 0.015 | 0.25 | < 0.06 | 1 | 8 | 0.5 | 256 | Resistant to all azoles only | CgPDR1, CgCDR1, CgFLR1 | ||
| CMRL-8 | 0.5 | 0.03 | 0.008 | 0.06 | < 0.06 | 0.5 | 0.25 | 0.25 | 4 | Susceptible to all | – | ||
| CMRL-9 | 1 | 0.03 | 0.015 | 0.25 | < 0.06 | 1 | 0.5 | 1 | 16 | Susceptible to all | – | ||
| CMRL-10 | 1 | 0.03 | < 0.008 | 0.5 | < 0.06 | 1 | 0.5 | 0.5 | 16 | Susceptible to all | – | ||
| CMRL-11 | 0.5 | 0.03 | < 0.008 | 0.03 | < 0.06 | 0.5 | 0.25 | 0.5 | 8 | Susceptible to all | – | ||
| CMRL-12 | 0.5 | 0.03 | 0.015 | 0.06 | < 0.06 | > 8 | 2 | 8 | 128 | Resistant to all azoles only | CgPDR1, CgCDR1, CgFLR1 | ||
| ATCC 90030 | 1 | 0.03 | 0.015 | 0.06 | < 0.06 | 1 | 0.5 | 0.5 | 8 | Susceptible to all | – | ||
| Abbreviations: MIC, minimum inhibitory concentration; AMB, amphotericin B; ANI, anidulafungin; CAS, caspofungin; FLC, fluconazole; ITR, itraconazole; MIF, micafungin; POS, posaconazole; VRC, voriconazole; 5-FC, 5-flucytosine. | |||||||||||||
Table 1. In vitro susceptibility of 13 Candida glabrata isolates including CMRL-1/CMRL-2, CMRL-3/CMRL-4 and CMRL-5/CMRL-6 isolate pairs obtained before and after antifungal therapy
| Standards | DNA Standard Volume (μL) | 1X TE buffer | Reagent (μL) | Total in 96-well plate (μL) | Final DNA Concentration (ng/mL) |
| Std-Pico 1 | 8 (Standard DNA tube 100 µg/mL) | 1992 | 100 | 200 | 1000 |
| Std-Pico 2 | 10 (from Std-Pico 1) | 90 | 100 | 200 | 100 |
| Std- Pico 3 | 5 (from Std-Pico 1) | 95 | 100 | 200 | 50 |
| Std-Pico 4 | 2 (from Std-Pico 1) | 198 | 100 | 200 | 10 |
| Std-Pico 5 | 10 (Std-Pico 4) | 90 | 100 | 200 | 1 |
| Blank | – | 100 | 100 | 200 | Blank |
Table 2. Protocol for Preparing Standards for Standard Curve Generation for DNA Quantification
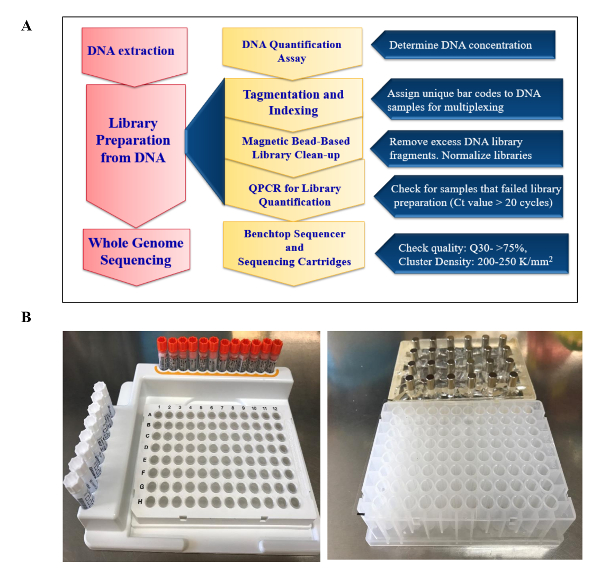
Figure 1. Sequencing Workflow: (A) An outline of major analytical steps for library preparation and sequencing on a benchtop sequencer. (B) Important components for DNA library preparation such as the (left to right) index plate rack for arrangement of indices during indexing and magnetic rack with deep 96-well plate for magnetic bead based clean-up of DNA libraries. Please click here to view a larger version of this figure.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||
| Index Set A |
N701 | N702 | N703 | N704 | N705 | N706 | N707 | N710 | N711 | N712 | N714 | N715 | |
| A | S502 | Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | Sample 6 | Sample 7 | Sample 8 | Sample 9 | Sample 10 | Sample 11 | Sample 12 |
| B | S503 | Sample 13 | Sample 14 | Sample 15 | Sample 16 | Sample 17 | Sample 18 | Sample 19 | Sample 20 | Sample 21 | Sample 22 | Sample 23 | Sample 24 |
| C | S505 | Sample 25 | Sample 26 | Sample 27 | Sample 28 | Sample 29 | Sample 30 | Sample 31 | Sample 32 | Sample 33 | Sample 34 | Sample 35 | Sample 36 |
| D | S506 | Sample 37 | Sample 38 | Sample 39 | Sample 40 | Sample 41 | Sample 42 | Sample 43 | Sample 44 | Sample 45 | Sample 46 | Sample 47 | Sample 48 |
| E | S507 | Sample 49 | Sample 50 | Sample 51 | Sample 52 | Sample 53 | Sample 54 | Sample 55 | Sample 56 | Sample 57 | Sample 58 | Sample 59 | Sample 60 |
| F | S508 | Sample 61 | Sample 62 | Sample 63 | Sample 64 | Sample 65 | Sample 66 | Sample 67 | Sample 68 | Sample 69 | Sample 70 | Sample 71 | Sample 72 |
| G | S510 | Sample 73 | Sample 74 | Sample 75 | Sample 76 | Sample 77 | Sample 78 | Sample 79 | Sample 80 | Sample 81 | Sample 82 | Sample 83 | Sample 84 |
| H | S511 | Sample 85 | Sample 86 | Sample 87 | Sample 88 | Sample 89 | Sample 90 | Sample 91 | Sample 92 | Sample 93 | Sample 94 | Sample 95 | Sample 96 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||
| Index Set B | N716 | N718 | N719 | N720 | N721 | N722 | N723 | N724 | N726 | N727 | N728 | N729 | |
| A | S502 | Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | Sample 6 | Sample 7 | Sample 8 | Sample 9 | Sample 10 | Sample 11 | Sample 12 |
| B | S503 | Sample 13 | Sample 14 | Sample 15 | Sample 16 | Sample 17 | Sample 18 | Sample 19 | Sample 20 | Sample 21 | Sample 22 | Sample 23 | Sample 24 |
| C | S505 | Sample 25 | Sample 26 | Sample 27 | Sample 28 | Sample 29 | Sample 30 | Sample 31 | Sample 32 | Sample 33 | Sample 34 | Sample 35 | Sample 36 |
| D | S506 | Sample 37 | Sample 38 | Sample 39 | Sample 40 | Sample 41 | Sample 42 | Sample 43 | Sample 44 | Sample 45 | Sample 46 | Sample 47 | Sample 48 |
| E | S507 | Sample 49 | Sample 50 | Sample 51 | Sample 52 | Sample 53 | Sample 54 | Sample 55 | Sample 56 | Sample 57 | Sample 58 | Sample 59 | Sample 60 |
| F | S508 | Sample 61 | Sample 62 | Sample 63 | Sample 64 | Sample 65 | Sample 66 | Sample 67 | Sample 68 | Sample 69 | Sample 70 | Sample 71 | Sample 72 |
| G | S510 | Sample 73 | Sample 74 | Sample 75 | Sample 76 | Sample 77 | Sample 78 | Sample 79 | Sample 80 | Sample 81 | Sample 82 | Sample 83 | Sample 84 |
| H | S511 | Sample 85 | Sample 86 | Sample 87 | Sample 88 | Sample 89 | Sample 90 | Sample 91 | Sample 92 | Sample 93 | Sample 94 | Sample 95 | Sample 96 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||
| Index Set C | N701 | N702 | N703 | N704 | N705 | N706 | N707 | N710 | N711 | N712 | N714 | N715 | |
| A | S513 | Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | Sample 6 | Sample 7 | Sample 8 | Sample 9 | Sample 10 | Sample 11 | Sample 12 |
| B | S515 | Sample 13 | Sample 14 | Sample 15 | Sample 16 | Sample 17 | Sample 18 | Sample 19 | Sample 20 | Sample 21 | Sample 22 | Sample 23 | Sample 24 |
| C | S516 | Sample 25 | Sample 26 | Sample 27 | Sample 28 | Sample 29 | Sample 30 | Sample 31 | Sample 32 | Sample 33 | Sample 34 | Sample 35 | Sample 36 |
| D | S517 | Sample 37 | Sample 38 | Sample 39 | Sample 40 | Sample 41 | Sample 42 | Sample 43 | Sample 44 | Sample 45 | Sample 46 | Sample 47 | Sample 48 |
| E | S518 | Sample 49 | Sample 50 | Sample 51 | Sample 52 | Sample 53 | Sample 54 | Sample 55 | Sample 56 | Sample 57 | Sample 58 | Sample 59 | Sample 60 |
| F | S520 | Sample 61 | Sample 62 | Sample 63 | Sample 64 | Sample 65 | Sample 66 | Sample 67 | Sample 68 | Sample 69 | Sample 70 | Sample 71 | Sample 72 |
| G | S521 | Sample 73 | Sample 74 | Sample 75 | Sample 76 | Sample 77 | Sample 78 | Sample 79 | Sample 80 | Sample 81 | Sample 82 | Sample 83 | Sample 84 |
| H | S522 | Sample 85 | Sample 86 | Sample 87 | Sample 88 | Sample 89 | Sample 90 | Sample 91 | Sample 92 | Sample 93 | Sample 94 | Sample 95 | Sample 96 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||
| Index Set D | N716 | N718 | N719 | N720 | N721 | N722 | N723 | N724 | N726 | N727 | N728 | N729 | |
| A | S513 | Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 | Sample 6 | Sample 7 | Sample 8 | Sample 9 | Sample 10 | Sample 11 | Sample 12 |
| B | S515 | Sample 13 | Sample 14 | Sample 15 | Sample 16 | Sample 17 | Sample 18 | Sample 19 | Sample 20 | Sample 21 | Sample 22 | Sample 23 | Sample 24 |
| C | S516 | Sample 25 | Sample 26 | Sample 27 | Sample 28 | Sample 29 | Sample 30 | Sample 31 | Sample 32 | Sample 33 | Sample 34 | Sample 35 | Sample 36 |
| D | S517 | Sample 37 | Sample 38 | Sample 39 | Sample 40 | Sample 41 | Sample 42 | Sample 43 | Sample 44 | Sample 45 | Sample 46 | Sample 47 | Sample 48 |
| E | S518 | Sample 49 | Sample 50 | Sample 51 | Sample 52 | Sample 53 | Sample 54 | Sample 55 | Sample 56 | Sample 57 | Sample 58 | Sample 59 | Sample 60 |
| F | S520 | Sample 61 | Sample 62 | Sample 63 | Sample 64 | Sample 65 | Sample 66 | Sample 67 | Sample 68 | Sample 69 | Sample 70 | Sample 71 | Sample 72 |
| G | S521 | Sample 73 | Sample 74 | Sample 75 | Sample 76 | Sample 77 | Sample 78 | Sample 79 | Sample 80 | Sample 81 | Sample 82 | Sample 83 | Sample 84 |
| H | S522 | Sample 85 | Sample 86 | Sample 87 | Sample 88 | Sample 89 | Sample 90 | Sample 91 | Sample 92 | Sample 93 | Sample 94 | Sample 95 | Sample 96 |
Table 3. Template of Different Index Arrangement
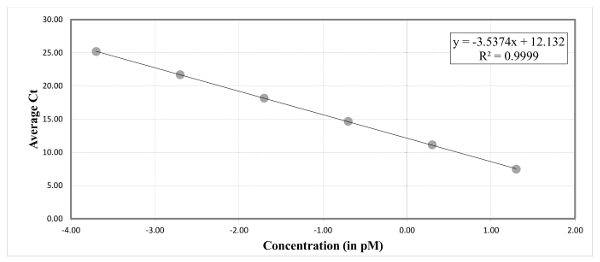
Figure 2: A standard graph generated with the Ct values of standards. Use the standard curve intercept and slope values to determine the average library concentration from Ct value of sample libraries in duplicates. Please click here to view a larger version of this figure.
| Metrics | Standard Values | Values Obtained (Average) |
| Yield | 32.5-50 Gb for mid-output | 42 Gb for mid-output |
| 100-130 Gb for high-output | 120 Gb for high-output | |
| Percentage Q30 | ≥ 75% | 80% |
| Cluster Density | 170-230 K/mm2, Optimal at 200 K/mm2 | 210 K/mm2. |
| Clusters Passing Filters | > 70% | 89.09% |
| Intensity by Cycle | Above 1000 for each tile in flowcell | Above 1500 for each tile in flowcell |
| Error Rate | Below 1.5 | 1.4 |
Table 4. Metrics for a standard sequencing run in Benchtop Sequencer
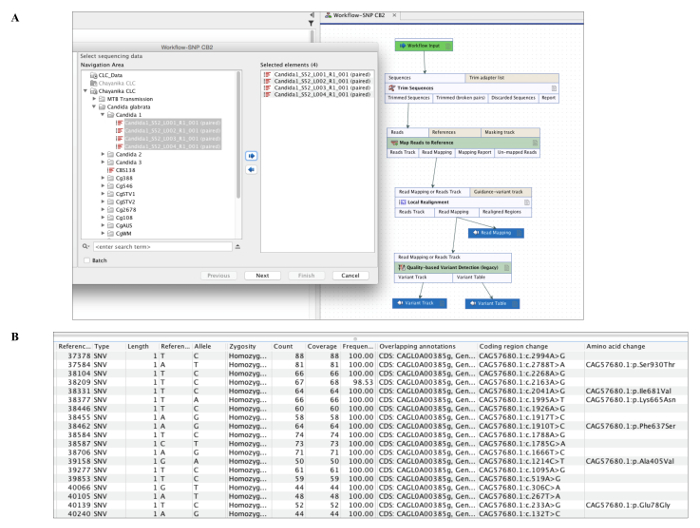
Figure 3: Sequencing Data Analysis Software. (A) Create a desired workflow including sequence trimming, mapping to reference and quality based variant detection. Run workflow by selecting sample FASTQ files (individual or multiple samples in batch). (B) List of structural variants showing reference position, coverage, nucleotide change and amino acid change obtained for analysis of sample sequences. Please click here to view a larger version of this figure.
| 1. Trim sequences | Setting Used |
| Trim Bases | Default settings |
| Filter on length with maximum number of nucleotide in reads | 1000 |
| Filter on length with minimum number of nucleotide in reads | 50 |
| 2. Mapping Reads to reference | |
| Reference selected | CBS138 |
| Reference masking with masking mode | No masking |
| Mapping Options | Default settings |
| 3. Local Realignment | |
| Alignment settings | Default settings |
| 4. Quality Based Variant Detection | |
| Neighbourhood radius | 5 |
| Minimum gap and mismatch count | 2 |
| Minimum neighbourhood quality | 15 |
| Minimum central quality | 20 |
| Read filters | Default settings |
| Minimum coverage | 4 |
| Minimum variant frequency (%) | 75 |
| Variant filters | Default settings |
| Maximum expected alleles (Ploidy) | 2 |
| Genetic code | Standard |
Table 5. Workflow Parameters and Settings on the Software
| Structural Variant Nucleotide Position | Gene | Drug(s) | Found in Number of Isolates |
Resistant Isolates | Susceptible Isolates | |
| SNP_Cg_95352_S629P_fks1 | CgFKS1 | CAS, ANI, MIF | 1 | CMRL-2 | – | |
| SNP_Cg_375361_S633P_fk2 | CgFKS2 | CAS, ANI, MIF | 1 | CMRL-4 | – | |
| SNP_Cg_285870_A237T_fcy2 | CgFCY2 | 5-FC | 2 | CMRL-6 | CMRL-5 | |
| SNP_Cg_286311_I384F_fcy2 | CgFCY2 | 5-FC | 2 | 0 | CMRL-1, CMRL-2 | |
| SNP_Cg_720995_C128F_erg9 | CgERG9 | FLC, POS, VRC, ITR | 3 | CMRL-6 | CMRL-5, CMRL-10 | |
| SNP_Cg_48683_R376Q_pdr1 | CgPDR1 | FLC, POS, VRC, ITR | 1 | CMRL-6 | – | |
| SNP_Cg_50384_G250N_pdr1 | CgPDR1 | FLC, POS, VRC, ITR | 1 | CMRL-7 | – | |
| SNP_Cg_49640_P695L_pdr1 | CgPDR1 | FLC, POS, VRC, ITR | 1 | 0 | CMRL-11 | |
| SNP_Cg_49858_N768D_pdr1 | CgPDR1 | FLC, POS, VRC, ITR | 1 | CMRL-12 | – | |
| SNP_Cg_203787_H58Y_cdr1 | CgCDR1 | FLC, POS, VRC, ITR | 5 | CMRL-6, CMRL-12 | CMRL-5, CMRL-10, CMRL-11 | |
| SNP_Cg_205529_M638I_cdr1 | CgCDR1 | FLC, POS, VRC, ITR | 1 | CMRL-7 | – | |
| SNP_Cg_206938_N1108S_cdr1 | CgCDR1 | FLC, POS, VRC, ITR | 1 | CMRL-7 | – | |
| SNP_Cg_589884_I116V_flr1 | CgFLR1 | FLC, POS, VRC, ITR | 4 | CMRL-7 | CMRL-1, CMRL-2, CMRL-9 | |
| SNP_Cg_589470_V254I_flr1 | CgFLR1 | FLC, POS, VRC, ITR | 1 | CMRL-12 | – | |
Table 6. Report of structural variant position in genes linked to antifungal drug resistance found in the number of isolates of C. glabrata
