Undersøkelser av sekundær metabolisme består ofte av screening av råoljeekstrakter for spesifikke biologiske aktiviteter etterfulgt av rensing, identifikasjon og karakterisering av bestanddelene som tilhører aktive fraksjoner. Denne prosessen har vist seg å være effektiv, fremme isolasjon av flere kjemiske enheter. Men i dag er dette sett på som umulig, hovedsakelig på grunn av de høye gjenoppdagelsene. Som den farmasøytiske industrien revolusjonert uten kunnskap om rollene og funksjonene til spesialiserte metabolitter, ble deres identifikasjon utført under laboratorieforhold som ikke nøyaktig representerer natur1. I dag er det en bedre forståelse av naturlige signalpåvirkninger, sekresjon og tilstedeværelsen av de fleste mål ved undetectably lave konsentrasjoner. I tillegg vil regulering av prosessen hjelpe fagmiljøet og farmasøytisk industri til å dra nytte av denne kunnskapen. Det vil også være til nytte for forskning som involverer direkte isolering av metabolitter relatert til stille biosyntetiske genklynger (BGCs)2.
I denne sammenheng har fremskritt i genomisk sekvensering fornyet interessen for screening av mikroorganismemetabolitter. Dette er fordi analyse av genomisk informasjon om avdekkede biosyntetiske klynger kan avsløre gener koding nye forbindelser som ikke er observert eller produsert under laboratorieforhold. Mange mikrobielle hele genomprosjekter eller utkast er tilgjengelige i dag, og antallet vokser hvert år, noe som gir massive utsikter for å avdekke nye bioaktive molekyler gjennom genomgruvedrift3,4.
Atlas of Biosynthetic Gene Clusters er den nåværende største samlingen av automatisk utvunnet genklynger som en del av den integrerte mikrobielle genomer plattformen til Joint Genome Institute (JGI IMG-ABC)2. Senest har minimumsinformasjonen for biosyntetiske genklynger (MIBiG) standardiseringsinitiativ fremmet manuell reannotasjon av BGCer, noe som gir et svært kuratert referansedatasett5. I dag er mange verktøy tilgjengelig for å muliggjøre beregningsmessig gruvedrift av genetiske data og deres forbindelse til kjente sekundære metabolitter. Ulike strategier har også blitt utviklet for å få tilgang til nye bioaktive naturlige produkter (dvs. heterologøst uttrykk, mål gensletting, in vitro rekonstituering, genomsekvens, isotop-guidet screening [genomisotopisk tilnærming], manipulering av lokale og globale regulatorer, resistens målbasert gruvedrift, kulturuavhengig gruvedrift, og, mer nylig, MS-guidet / kode tilnærminger2,6,7,8,9, 10,11,12,13,14,15).
Genomgruvedrift som en enestående strategi krever innsats for å kommentere en enkelt eller liten gruppe molekyler; Dermed forblir hull i prosessen der nye forbindelser prioriteres for isolasjon og strukturbelysning. I prinsippet retter disse tilnærmingene seg bare mot én biosyntetisk vei per eksperiment, og resulterer dermed i en langsom oppdagelsesfrekvens. I denne forstand, ved hjelp av GM sammen med en molekylær nettverk tilnærming representerer et viktig fremskritt for naturlig produktforskning14,15.
Allsidigheten, nøyaktigheten og den høye følsomheten til flytende kromatografi-massespektrometri (LC-MS) gjør det til en god metode for sammensatt identifikasjon. Foreløpig har flere plattformer investert algoritmer og programvaresuiter for umålrettede metabolomikk16,17,18,19,20. Kjernen i disse programmene inkluderer funksjonsdeteksjon (toppplukking)21 og toppjustering, noe som gjør det mulig å matche identiske funksjoner på tvers av en gruppe prøver og søke etter mønstre. MS mønsterbaserte algoritmer22,23 sammenligner karakteristiske fragmenteringsmønstre og samsvarer med MS2-likheter som genererer molekylære familier som deler strukturelle funksjoner. Disse funksjonene kan deretter fremheves og grupperes, og gir muligheten til raskt å oppdage kjente2og ukjente molekyler fra et komplekst biologisk ekstrakt av tandem MS2,24,,25. Derfor er tandem MS en allsidig metode for å få strukturell informasjon om flere kjemotyper som finnes i en stor mengde data samtidig.
Den globale naturlige produkter social molecular networking (GNPS)26 algoritmen bruker normalisert fragment ioner intensitet for å konstruere flerdimensjonale vektorer, der likheter sammenlignes ved hjelp av en cosinusfunksjon. Forholdet mellom ulike overordnede ioner tegnes inn i en diagramrepresentasjon, der hver fragmentering visualiseres som en node (sirkler), og sammenhengen til hver node defineres av en kant (linjer). Den globale visualiseringen av molekyler fra en enkelt kilde er definert som et molekylært nettverk. Strukturelt divergerende molekyler som fragmenterer unikt vil danne sin egen spesifikke klynge eller konstellasjon, mens relaterte molekyler klynger seg sammen. Clustering kjemotyper tillater hypotetisk tilkobling av lignende strukturelle funksjoner til deres biosyntetiske opprinnelse.
Kombinere både kjemotype-til-genotype og genotype-til-kjemotype tilnærminger er kraftig når du oppretter bioinformatikk koblinger mellom BGCs og deres små molekylprodukter27. Derfor er MS-guidet genomgruvedrift en rask metode og lav materialkrevende strategi, og det bidrar til å bygge bro over foreldreioner og biosyntetiske veier avslørt av WGS av en eller flere stammer under ulike metabolske og miljømessige forhold.
Arbeidsflyten til denne protokollen (Figur 1) består av fôring AV WGS-data til en biosyntetisk genklyngemerknadsplattform som antiSMASH28,,29,30. Det bidrar til å estimere mangfoldet av forbindelser og klasse av forbindelser kodet av genomet. En strategi for å målrette en biosyntetisk genklynge som koding en kjemisk enhet av interesse må vedtas, og kulturekstrakter fra en vill type stamme og / eller heterologous stamme som inneholder BGC kan analyseres for å generere grupperte ioner basert på likheter ved hjelp av GNPS26,31. Følgelig er det mulig å identifisere nye molekyler som forbinder med målrettet BGC og er utilgjengeligi databasen (hovedsakelig ukjente analoger, noen ganger produsert i lave titers). Det er relevant å vurdere at brukerne kan bidra til disse plattformene, og at tilgjengeligheten av bioinformatikk og MS/ MS-data øker raskt, og driver til en konstant utvikling og oppgradering av effektive beregningsverktøy og algoritmer for å veilede effektive forbindelser av komplekse ekstrakter med molekyler.
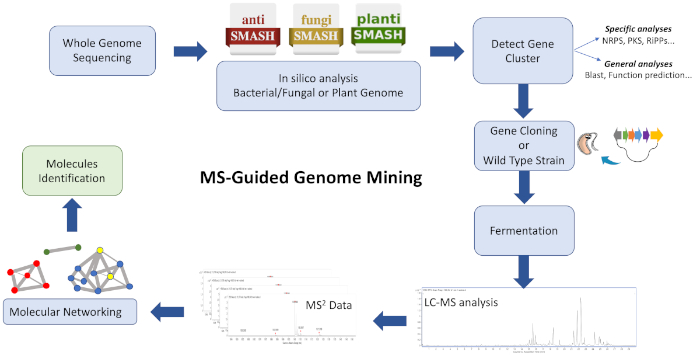
Figur 1: Oversikt over hele arbeidsflyten. Vist er en illustrasjon av bioinformatikk, kloning og molekylære nettverkstrinn involvert i den beskrevne MS-guidede genomgruvetilnærmingen for å identifisere nye metabolitter. Vennligst klikk her for å se en større versjon av denne figuren.
Denne protokollen beskriver en rask og effektiv arbeidsflyt for å kombinere genomgruvedrift og molekylært nettverk som utgangspunkt for den naturlige produktoppdagelsesrørledningen. Selv om mange applikasjoner er i stand til å visualisere sammensetningen og sammenhengen til MS-påviselige molekyler i ett nettverk, er flere vedtatt her for å visualisere strukturelt lignende grupperte molekyler. Ved hjelp av denne strategien, romanen cyclodepsipeptid produkter observert i metabolske ekstrakter av Streptomyces sp. CBMAI 2042 er vellykket identifisert. Guidet av genom gruvedrift, hele biosyntetiske genklynge koding for valinomycins er anerkjent og klonet inn i produsenten stamme Streptomyces coelicolor M1146. Til slutt, etter et MS-mønsterbasert molekylært nettverk, er molekylene som oppdages av MS korrelert med BGCs ansvarlig for deres biogenesis32.
