Salient object detection mimics human visual attention, swiftly identifying key image regions while suppressing background information. This technique is widely employed as a pre-processing tool in tasks such as image cropping1, semantic segmentation2, and image editing3. It streamlines tasks like background replacement and foreground extraction, improving editing efficiency and precision. Additionally, it aids in semantic segmentation by enhancing target localization. The potential of salient object detection to enhance computational efficiency and conserve memory underscores its significant research and application prospects.
Over the years, salient object detection has evolved from initial traditional algorithms to the incorporation of deep learning algorithms. The objective of these advancements has been to narrow the gap between salient object detection and human visual mechanisms. This has led to the adoption of deep convolutional network models for the study of salient object detection. Borji et al.4 summarized and generalized most of the classical traditional algorithms, which rely on the underlying features of the image. Despite some improvement in detection accuracy, manual experience, and cognition continue to pose challenges for salient object detection in complex environments.
The use of Convolutional Neural Networks (CNNs) is prevalent in the domain of salient object detection. In this context, deep convolutional neural networks are utilized for weight updates through autonomous learning. Convolutional neural networks have been employed to extract contextual semantics from images through the use of cascaded convolutional and pooling layers, enabling the learning of complex image features at higher levels, which have higher discrimination and characterization ability for salient object detection in different environments.
In 2016, fully convolutional neural networks5 gained significant traction as a popular approach for salient object detection, based on which researchers started pixel-level salient object detection. Many models are usually built on existing networks (e.g., VGG166, ResNet7), aimed at enhancing image representation and strengthening the effect of edge detection.
Liu et al.8 used an already-trained neural network as the framework to compute the image globally and then refined the object boundary using a hierarchical network. The combination of the two networks forms the final deep saliency network. This was accomplished by feeding the previously acquired salient map into the network as prior knowledge in a repetitive manner. Zhang et al.9 effectively fused image semantic and spatial information using deep networks with bidirectional information transfer from shallow to deep and from deep to shallow layers, respectively. The detection of salient objects using a mutual learning deep model was put forward by Wu et al.10. The model utilizes foreground and edge information within a convolutional neural network to facilitate the detection process. Li et al.11 employed the 'hole algorithm' of neural networks to address the challenge of fixing the receptive fields of diverse layers in deep neural networks in the context of salient object detection. However, super-pixel segmentation is used for object edge acquisition, greatly increasing the computational effort and computing time. Ren et al.12 devised a multi-scale encoder-decoder network to detect salient objects and utilized convolutional neural networks to effectively combine deep and shallow features. Although the challenge of boundary blurring in object detection is resolved through this approach, the multi-scale fusion of information unavoidably results in heightened computational demands.
The literature review13 proposes that saliency detection, from traditional methods to deep learning methods, is summarized, and the evolution of saliency target detection from its origins to the era of deep learning can be seen very clearly. Various RGB-D-based salient object detection models with good performance have been proposed in the literature14. The above literature reviews and classifies the various types of algorithms for saliency object detection and describes their application scenarios, the databases used, and the evaluation metrics. This article also provides a qualitative and quantitative analysis of the proposed algorithms concerning their suggested databases and evaluation metrics.
All the above algorithms have obtained remarkable results in public databases, providing a basis for salient object detection in complex environments. Although there have been numerous research achievements in this field both domestically and internationally, there are still some issues to be addressed. (1) Traditional non-deep learning algorithms tend to have low accuracy due to their reliance on manually labeled features such as color, texture, and frequency, which can be easily affected by subjective experience and perception. Consequently, the precision of their salient object detection capabilities is diminished. Detecting salient objects in complex environments using traditional non-deep learning algorithms is challenging due to their difficulty in handling intricate scenarios. (2) Conventional methods for salient object detection exhibit limited accuracy due to their dependence on manually labeled features such as color, texture, and frequency. Additionally, region-level detection can be computationally expensive, often ignoring spatial consistency, and tends to poorly detect object boundaries. These issues need to be addressed to enhance the precision of salient object detection. (3) Salient object detection in intricate environments presents a challenge for most algorithms. Most salient object detection algorithms face serious challenges due to the increasingly complex salient object detection environment with variable backgrounds (similar background and foreground colors, complex background textures, etc.), many uncertainties such as inconsistent detection object sizes, and the unclear definition of foreground and background edges.
Most of the current algorithms exhibit low accuracy in detecting salient objects in complex environments with similar background and foreground colors, complex background textures, and blurred edges. Although current deep learning-based salient object algorithms demonstrate higher accuracy than traditional detection methods, the underlying image features they utilize still fall short in characterizing semantic features effectively, leaving room for improvement in their performance.
In summary, this study proposes an end-to-end deep neural network for a salient object detection algorithm, aiming to enhance the accuracy of salient object detection in complex environments, improve target edges, and better characterize semantic features. The contributions of this paper are as follows: (1) The first network employs VGG16 as the base network and modifies its five pooling layers using the 'hole algorithm'11. The pixel-level multi-scale fully convolutional neural network learns image features from different spatial scales, addressing the challenge of static receptive fields across various layers of deep neural networks and enhancing the detection accuracy in significant areas of focus in the field. (2) Recent efforts to improve the accuracy of salient object detection have focused on leveraging deeper neural networks, such as VGG16, to extract both depth features from the encoder network and shallow features from the decoder network. This approach effectively enhances the detection accuracy of object boundaries and improves semantic information, particularly in complex environments with variable backgrounds, inconsistent object sizes, and indistinct boundaries between foreground and background. (3) Recent endeavors to enhance the precision of salient object detection have emphasized the use of deeper networks, including VGG16, for extracting deep features from the encoder network and shallow features from the decoder network. This approach has demonstrated improved detection of object boundaries and greater semantic information, especially in complex environments with varying backgrounds, object sizes, and indistinct boundaries between the foreground and background. Additionally, the integration of a fully connected conditional random field (CRF) model has been implemented to augment the spatial coherence and contour precision of salient maps. The effectiveness of this approach was evaluated on SOD and ECSSD datasets with complex backgrounds and was found to be statistically significant.
Related work
Fu et al.15 proposed a joint approach using RGB and deep learning for salient object detection. Lai et al.16 introduced a weakly supervised model for salient object detection, learning saliency from annotations, primarily utilizing scribble labels to save annotation time. While these algorithms presented a fusion of two complementary networks for saliency object detection, they lack in-depth investigation into saliency detection under complex scenarios. Wang et al.17 designed a two-mode iterative fusion of neural network features, both bottom-up and top-down, progressively optimizing the results of the previous iteration until convergence. Zhang et al.18 effectively fused image semantic and spatial information using deep networks with bidirectional information transfer from shallow to deep and from deep to shallow layers, respectively. The detection of salient objects using a mutual learning deep model was proposed by Wu et al.19. The model utilizes foreground and edge information within a convolutional neural network to facilitate the detection process. These deep neural network-based salient object detection models have achieved remarkable performance on publicly available datasets, enabling salient object detection in complex natural scenes. Nevertheless, designing even more superior models remains an important objective in this research field and serves as the primary motivation for this study.
Overall framework
The proposed model's schematic representation, as depicted in Figure 1, is primarily derived from the VGG16 architecture, incorporating both a pixel-level multiscale fully convolutional neural network (DCL) and a deep encoder-decoder network (DEDN). The model eliminates all final pooling and fully connected layers of VGG16 while accommodating input image dimensions of W × H. The operational mechanism involves the initial processing of the input image via the DCL, facilitating the extraction of deep features, while shallow features are obtained from the DEDN networks. The amalgamation of these characteristics is subsequently subjected to a fully connected conditional random field (CRF) model, augmenting the spatial coherence and contour accuracy of the saliency maps produced.
To ascertain the model's efficacy, it underwent testing and validation on SOD20 and ECSSD21 datasets with intricate backgrounds. After the input image passes through the DCL, different scale feature maps with various receptive fields are obtained, and contextual semantics are combined to produce a W × H salient map with inter-dimensional coherence. The DCL employs a pair of convolutional layers with 7 x 7 kernels to substitute the final pooling layer of the original VGG16 network, enhancing the preservation of spatial information in the feature maps. This, combined with contextual semantics, produces a W × H salient map with inter-dimensional coherence. Similarly, the Deep Encoder-Decoder Network (DEDN) utilizes convolutional layers with 3 x 3 kernels in the decoders and a single convolutional layer after the last decoding module. Leveraging deep and shallow features of the image, it is possible to generate a salient map with a spatial dimension of W × H, addressing the challenge of indistinct object boundaries. The study describes a pioneering technique for salient object detection that amalgamates the DCL and DEDN models into a unified network. The weights of these two deep networks are learned through a training process, and the resultant saliency maps are merged and then refined using a fully connected Conditional Random Field (CRF). The primary objective of this refinement is to improve spatial consistency and contour localization.
Pixel-level multiscale fully convolutional neural network
The VGG16 architecture originally consisted of five pooling layers, each with a stride of 2. Each pooling layer compresses the image size to increase the number of channels, obtaining more contextual information. The DCL model is inspired by literature13 and is an improvement on the framework of VGG16. In this article, a pixel-level DCL model11 is used, as shown in Figure 2 within the architecture of VGG16, a deep convolutional neural network. The initial four maximum pooling layers are interconnected with three kernels. The first kernel is 3 × 3 × 128; the second kernel is 1 × 1 × 128; and the third kernel is 1 × 1 × 1. To achieve a uniform size of feature maps after the initial four pooling layers, connected to three kernels, with each size being equivalent to one-eighth of the original image, the step size of the first kernel connected to these four largest pooling layers is set to 4, 2, 1, and 1, respectively.
To preserve the original receptive field in the different kernels, the "hole algorithm" proposed in literature11 is used to extend the size of the kernel by adding zeros, thus maintaining the integrity of the kernel. These four feature maps are connected to the first kernel with different step sizes. Consequently, the feature maps produced in the final stage possess identical dimensions. The four feature maps constitute a set of multi-scale features obtained from distinct scales, each representing varying sizes of receptive fields. The resultant feature maps obtained from the four intermediate layers are concatenated with the ultimate feature map derived from VGG16, thus generating a 5-channel output. The ensuing output is subsequently subjected to a 1 × 1 × 1 kernel with the sigmoid activation function, ultimately producing the salient map (with a resolution of one-eighth of the original image). The image is up-sampled and enlarged using bilinear interpolation, ensuring that the resultant image, referred to as the saliency map, maintains an identical resolution as the initial image.
Deep encoder-decoder network
Similarly, the VGG16 network is employed as the backbone network. VGG16 is characterized by a low number of shallow feature map channels but high resolution and a high number of deep feature channels but low resolution. Pooling layers and down-sampling increase the computational speed of the deep network at the cost of reducing its feature map resolution. To address this issue, following the analysis in literature14, the encoder network is used to modify the full connectivity of the last pooling layer in the original VGG16. This modification involves replacing it with two convolutional layers with 7 × 7 kernels (larger convolutional kernels increase the receptive field). Both convolution kernels are equipped with a normalization (BN) operation and a modified linear unit (ReLU). This adjustment results in an encoder output feature map that better preserves image space information.
While the encoder improves high-level image semantics for the global localization of salient objects, the boundary-blurring problem of its salient object is not effectively improved. To tackle this issue, deep features are fused with shallow features, inspired by edge detection work12, proposing the encoder-decoder network model (DEDN) as shown in Figure 3. The encoder architecture comprises three kernels interconnected with the initial four, while the decoder systematically enhances the feature map resolution using the maximum values retrieved from the maximum pooling layers.
In this innovative methodology for salient object detection, during the decoder phase, a convolutional layer with a 3 × 3 kernel is utilized in combination with a batch normalization layer and an adapted linear unit. At the conclusion of the final decoding module within the decoder architecture, a solitary-channel convolutional layer is employed to procure a salient map of spatial dimensions W × H. The salient map is generated through a collaborative fusion of the encoder-decoder model, yielding the outcome, and the complementary fusion of the two-i.e., the complementary fusion of deep information and shallow information. This not only achieves accurate localization of the salient object and increases the receptive field but also effectively preserves image detail information and strengthens the boundary of the salient object.
Integration mechanism
The encoder architecture comprises three kernels, which are associated with the initial four maximum pooling layers of the VGG16 model. In contrast, the decoder is intentionally formulated to progressively augment the resolution of feature maps acquired from the up-sampling layers by harnessing the maximum values garnered from the corresponding pooling layers. A convolutional layer utilizing a 3 x 3 kernel,a batch normalization layer, and a modified linear unit are then utilized in the decoder, followed by a single-channel convolutional layer to generate a salient map of dimensions W × H. The weights of the two deep networks are learned through alternating training cycles. The first network's parameters were kept fixed, while the second network's parameters underwent training for a total of fifty cycles. During the process, the weights of the saliency map (S1 and S2) used for fusion are updated via a random gradient. The loss function11 is:
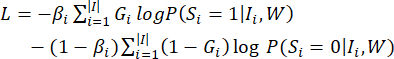 (1)
(1)
In the given expression, the symbol G represents the manually labeled value, while W signifies the complete set of network parameters. The weight βi serves as a balancing factor to regulate the proportion of salient pixels versus non-salient pixels in the computation process.
The image I is characterized by three parameters: |I|, |I|– and |I|+, which represent the total number of pixels, the count of non-salient pixels, and the count of salient pixels, respectively. 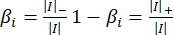
Since the salient maps obtained from the above two networks do not consider the coherence of neighboring pixels, a fully connected pixel-level saliency refinement model CRF15 is used to improve spatial coherence. The energy equation11 is as follows, solving the binary pixel labeling problem.
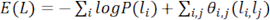 (2)
(2)
where L denotes the binary label (salient value or non-salient value) assigned to all pixels. The variable P(li) denotes the likelihood of a given pixel xi being assigned a specific label li, indicating the likelihood of the pixel xi being saliency. In the beginning, P(1) = Si and P(0) = 1 – Si, where Si denote the saliency value at the pixel xi within the fused saliency map S. θi,j(li,lj) is the pairwise potential, defined as follows.
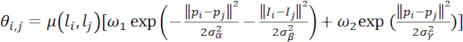 (3)
(3)
Among them, if li ≠ lj, then μ(li,lj) = 1, otherwise μ(li,lj) = 0. The computation of θi,j involves the utilization of two kernels, where the initial kernel is dependent on both the pixel position P and the pixel intensity I. This results in the proximity of pixels with similar colors exhibiting comparable saliency values. The two parameters, σα and σβ, regulate the extent to which color similarity and spatial proximity influence the outcome. The objective of the second kernel is to eliminate isolated small regions. The minimization of energy is achieved through high-dimensional filtering, which expedites the mean field of the Conditional Random Field (CRF) distribution. Upon computation, the salient map denoted as Scrf exhibits enhanced spatial coherence and contour with regards to the salient objects detected.
Experimental configurations
In this article, a deep network for salient target detection based on the VGG16 neural network is constructed using Python. The proposed model is compared with other methods using the SOD20 and ECSSD21 datasets. The SOD image database is known for its complex and cluttered backgrounds, similarity in colors between foreground and background, and small object sizes. Each image in this dataset is assigned a manually labeled true value for both quantitative and qualitative performance evaluation. On the other hand, the ECSSD dataset primarily consists of images sourced from the Internet, featuring more complex and realistic natural scenes with low contrast between the image background and salient objects.
The evaluation indexes used to compare the model in this paper include the commonly used Precision-Recall curve, Fβ and EMAE. To quantitatively assess the predicted saliency map, the Precision-Recall (P-R) curve22 is employed by altering the threshold from 0 to 255 for binarizing the saliency map. Fβ is a comprehensive assessment metric, calculated with the precision and recall equations derived from the binarized salient map and a true value map.
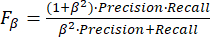 (4)
(4)
where β is the weight parameter to adjust the accuracy and recall, setting β2 = 0.3. The calculation of EMAE is equivalent to computing the mean absolute error between the resultant saliency map and the ground truth map, as defined by the ensuing mathematical expression:
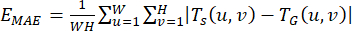 (5)
(5)
Let Ts (u,v) denote the extracted value of the salient map (u,v) pixels, and let TG (u,v) denote the corresponding value of the true map (u,v) pixels.
This study introduces an end-to-end deep neural network comprising two complementary networks: a pixel-level multi-scale fully convolutional network and a deep encoder-decoder network. The first network integrates contextual semantics to derive visual contrasts from multi-scale feature maps, addressing the challenge of fixed receptive fields in deep neural networks across different layers. The second network utilizes both deep and shallow image features to mitigate the issue of blurred boundaries in target objects. Finally, a fully connected conditional random field (CRF) model is applied to improve the spatial coherence and contours of the saliency map.
The study conducts a qualitative and quantitative comparison between the proposed algorithm and ten existing algorithms in the field. Experimental results demonstrate the effectiveness of the proposed algorithm in enhancing the accuracy of significant object detection. Moreover, the algorithm shows potential applicability in power visual tasks, offering promising prospects in various complex environments within the domain of intelligent power grids.
Ablation experiments
The current investigation has executed a series of ablation experiments on the SOD database to evaluate the algorithm's effectiveness. The outcomes of said experiments are detailed in Table 1. (1) The evaluation metrics used to compare the model are the Precision-Recall curve22, Fβ and EMAE. Table 1 (No. 1) results show that the removal of the DCL model from the algorithm causes a decrease in the Fβ value and an increase in the EMAE value. The aforementioned observation suggests that Dynamic Convolutional Layers (DCL) may have the capacity to bolster the efficacy of deep neural networks by integrating dynamic receptive fields into diverse layers, which, in turn, can heighten the visual contrast of multi-scaled feature maps. (2) From Table 1 (No.2), we can see that the algorithm in this paper only deletes the DEDN structure, comparing with the complete module in Table 1 (No.3), the F_β value in Table 1 (No.2) decreases and the E_MAE value increases, which indicates that the DEDN can effectively and accurately locate the prominence, increase the receptive field, and retain the detailed information of the image, while reinforcing the boundaries of the prominence.
Figure 6 presents the visualization results of the ablation experiment. The images are arranged from left to right, showcasing the original image, the DCL algorithm result, the DEDN algorithm result, the proposed algorithm in this paper, and the corresponding ground-truth image. Upon closer inspection of Figure 6, it is evident that the DCL algorithm tends to describe the target boundary when detecting images in the SOD database but struggles to effectively filter the background. The DEDN algorithm, on the other hand, strengthens the target boundary but faces challenges in suppressing background redundancy information. In contrast, the algorithm proposed in this paper combines the strengths of these two algorithms in a complementary manner, effectively highlighting the target while suppressing redundancy information from complex backgrounds. The results of this paper surpass those of either algorithm alone.
Comparison with other advanced algorithms
To evaluate the performance of the proposed algorithm, a comparative analysis was conducted with eleven prominent salient object detection methods, namely GMR23, GS24, SF25, PD26, SS27, DRFI28, MDF29, ELD30, DHS31, and DCL11. Among them, GMR23, GS24, SF25, PD26, SS27, and DRFI28 are well-performing traditional unsupervised saliency detection methods commonly employed as benchmarks by many deep saliency models. The remaining four methods leverage deep convolutional neural networks and have demonstrated superior performance in their respective research literature. The evaluation metrics employed for this study include PR curves, maximum F-measure values, and mean absolute error (MAE). The selected test datasets comprise SOD and ECSSD datasets.
Quantitative comparison
Figure 7 illustrates the precision-recall (PR) curves comparing the algorithm proposed in this study with 10 other prominent salient object detection methods on the SOD and ECSSD publicly available image datasets. The curves clearly indicate that the algorithm proposed in this study outperforms the other 10 algorithms, thereby validating the superior detection performance of the method presented in this paper. Of particular note is this algorithm's ability to sustain high precision even as the recall approaches 1, indicating its accurate segmentation of visually salient objects while ensuring their integrity. Table 2 provides a quantitative comparison of the methods on the SOD and ECSSD test datasets, revealing that our algorithm achieves better performance in terms of the maximum F-measure (Fβ) and mean absolute error (EMAE), primarily attributed to the complementary combination of the DCL network and the DEDN network.
Qualitative comparison
Furthermore, a qualitative assessment was conducted to juxtapose the visual outcomes of the analyzed techniques, as illustrated in Figure 8. These figures showcase a sequence of images arranged from left to right, starting with the original images, followed by GMR23, GS24, SF25, PD26, SS27, DRFI28, MDF29, ELD30, DHS31, and DCL11, the algorithm proposed in this article and the Ground-truth map.
In Figure 8A, a qualitative comparison in the SOD dataset is presented. It is evident that the original image in column 1 exhibits a relatively similar color distribution between the background and foreground elements. Additionally, the first and third saliency maps present a more intricate background texture, potentially impeding the detection of the salient object. The algorithm outlined in this study shows a significant improvement in the detection of salient objects in complex environments, surpassing the performance of other existing algorithms. The initial image in column 1, particularly the second image, contains background branches that are intermingled with the foreground animal, posing a challenge for correct assessments of the foreground object. The algorithm put forth in this study successfully addresses the issue of background interference and effectively highlights the foreground object region. The experiment demonstrates that the algorithm proposed achieves high accuracy and precision in dealing with images with complex backgrounds.
In Figure 8B, a qualitative comparison within the ECSSD dataset is presented, showcasing the visual contrast results of various salient object detection methods. The findings indicate that the proposed algorithm achieves superior detection performance across diverse and complex natural scenes. These natural scene images encompass scenarios such as salient objects in contact with image boundaries in the first and second images and low contrast and color similarity between the foreground and background in the third image. Through these visualized outcomes, the algorithm proposed here effectively highlights complete salient objects while ensuring clear object boundaries. Regardless of the scale of salient objects, whether they are large or small, the algorithm consistently exhibits high segmentation accuracy, validating its effectiveness. Furthermore, compared to other methods, the algorithm presented in this study demonstrates higher robustness, mitigating false detections in saliency regions (or background regions).
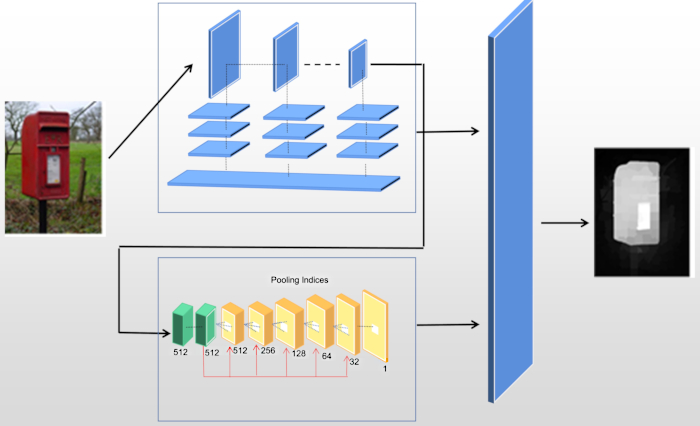
Figure 1: Overall structure framework. Schematic representation of the proposed model. Please click here to view a larger version of this figure.
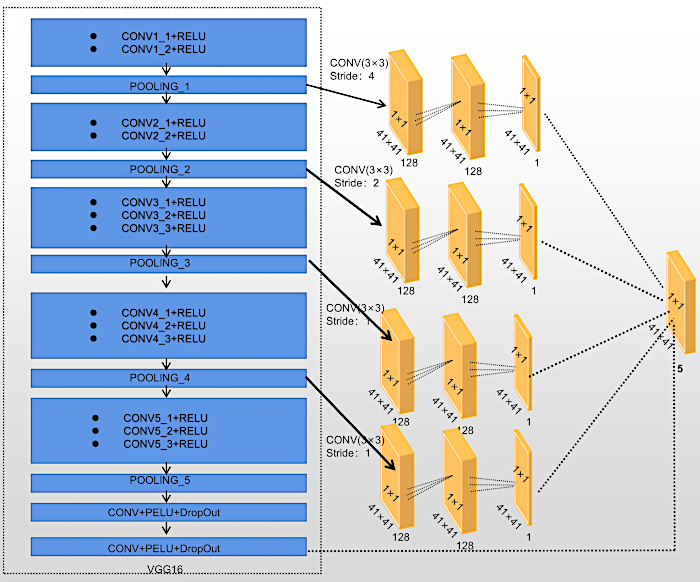
Figure 2: The pixel-level DCL model. A pixel-level DCL model is used within the architecture of VGG16, a deep convolutional neural network. The initial four maximum pooling layers are interconnected with three kernels. Please click here to view a larger version of this figure.
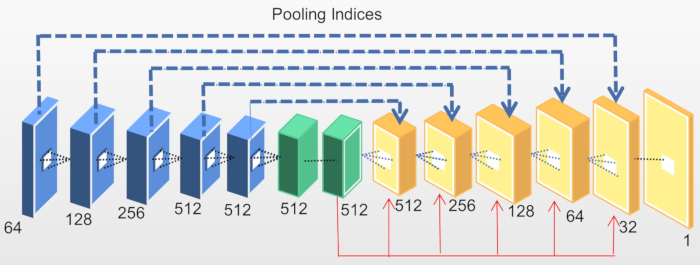
Figure 3: Encoding-decoding network model (DEDN). Deep features are fused with shallow features inspired by the edge detection work, proposing the encoder-decoder network model (DEDN). Please click here to view a larger version of this figure.
Figure 4: The GUI interface. The code is run to generate a GUI interface for easy operation. Please click here to view a larger version of this figure.
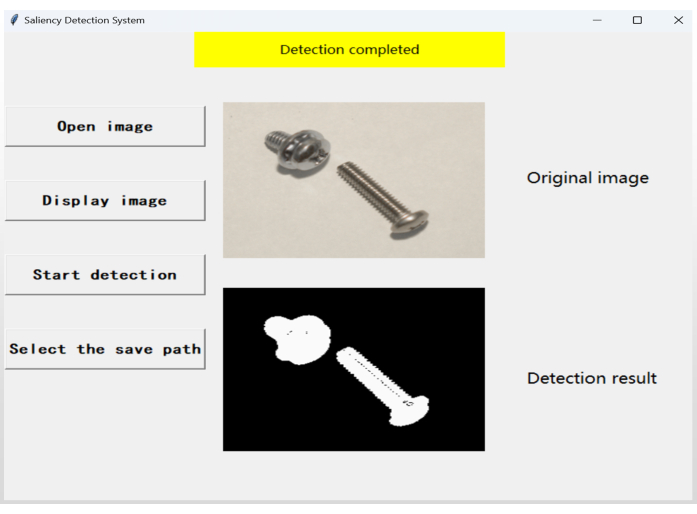
Figure 5: GUI interface demo. GUI interface presentation for easy comparison of test image results. Please click here to view a larger version of this figure.

Figure 6: The visualization results of the ablation experiment. (A) The original image, (B) the DCL algorithm, (C) the DEDN algorithm, (D) the algorithm used in the current study, and (E) the corresponding ground-truth image are shown from left to right. As can be seen from Figure 6, (B) the DCL algorithm can only describe the target boundary when detecting images, and the background is difficult to filter. (C) The DEDN algorithm has the effect of strengthening the target boundary, but it is equally difficult to suppress the background redundancy information; while (D) the algorithm in this paper combines these two algorithms in a complementary way, highlighting the target while suppressing the redundancy information of the complex background. Please click here to view a larger version of this figure.
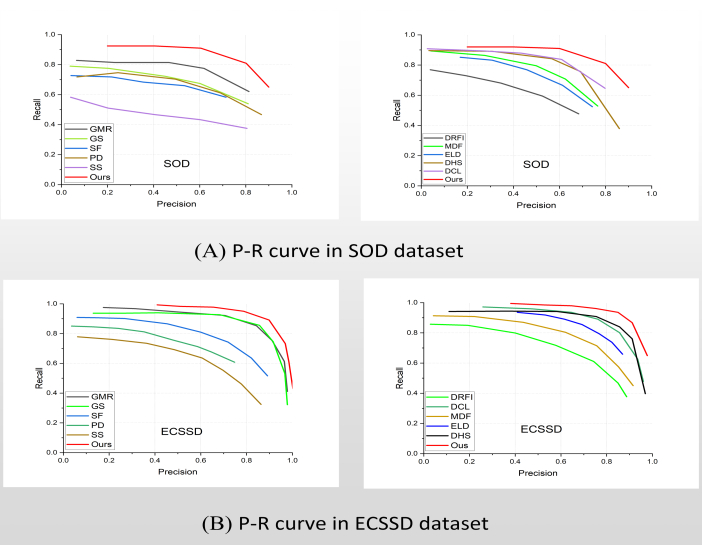
Figure 7: P-R curve. (A) P-R curves are in SOD databases and (B) P-R curves are in ECSSD databases respectively. The P-R curves of this study's algorithm in both (A) and (B) are higher than those of the other 10 algorithms, which is proved that the algorithm in this paper has high accuracy relative to these 10 algorithms. Please click here to view a larger version of this figure.

Figure 8: Qualitative comparison. Qualitative comparison of different salient object detection algorithms in the SOD databases (A) and ECSSD databases (B) respectively.The original input images are presented from left to right, GMR, GS, SF, PD, SS, DRFI, MDF, ELD, DHS, and DCL, the algorithm proposed in this study and the Ground-truth map. As seen in (A), the algorithm outlined provides a significant improvement in the detection of salient objects in complex environments, surpassing the performance of other existing algorithms. As can be seen in (B), the algorithm proposed in this study has higher robustness compared to other methods because it reduces the false detection of salient (or background) regions. Please click here to view a larger version of this figure.
| No. | Module setting | Fβ | EMAE |
| NO.1 | Removing DCL only | 0.835 | 0.117 |
| NO.2 | Removing DEDN only | 0.832 | 0.126 |
| NO.3 | Complete Module | 0.854 | 0.110 |
Table 1: Results of ablation experiments.
| Model | SOD | ECSSD | ||
| Fβ | EMAE | Fβ | EMAE | |
| GMR | 0.740 | 0.148 | 0.476 | 0.189 |
| GS | 0.677 | 0.188 | 0.355 | 0.344 |
| SF | 0.779 | 0.150 | 0.309 | 0.230 |
| PD | 0.720 | 0.162 | 0.358 | 0.248 |
| SS | 0.574 | 0.225 | 0.268 | 0.344 |
| DRFI | 0.801 | 0.127 | 0.516 | 0.166 |
| MDF | 0.709 | 0.150 | 0.832 | 0.105 |
| ELD | 0.737 | 0.154 | 0.869 | 0.078 |
| DHS | 0.812 | 0.127 | 0.907 | 0.059 |
| DCL | 0.786 | 0.131 | 0.901 | 0.068 |
| This study | 0.854 | 0.110 | 0.938 | 0.044 |
Table 2: The maximum F-measure values (Fβ) and MAE (Mean Absolute Error) values of various algorithms across two image datasets.
