ट्रांसक्रिप्टोम में एक नमूने में सभी जीनों के भाव होते हैं और इसे माइक्रोएरे और आरएनए-सीक्यू1 जैसी उच्च-थ्रूपुट तकनीकों द्वारा प्रोफाइल किया जा सकता है। डेटासेट में एक जीन के अभिव्यक्ति स्तर को ट्रांसक्रिप्टोमिक फीचर कहा जाता है, और फेनोटाइप और नियंत्रण समूहों के बीच एक ट्रांसक्रिप्टोमिक फीचर का अंतर प्रतिनिधित्व इस जीन को इस फेनोटाइप 2,3 के बायोमार्कर के रूप में परिभाषित करता है। ट्रांसक्रिप्टोमिक बायोमार्कर का उपयोग रोग निदान4, जैविक तंत्र5, और उत्तरजीविता विश्लेषण 6,7, आदि की जांच में बड़े पैमाने पर किया गया है।
स्वस्थ ऊतकों में जीन गतिविधि पैटर्न 8,9 जीवन के बारे में महत्वपूर्ण जानकारी ले. ये पैटर्न अमूल्य अंतर्दृष्टि प्रदान करते हैं और सौम्य विकारों 10,11 और घातक रोगों12 के जटिल विकास प्रक्षेपवक्र को समझने के लिए आदर्श संदर्भ के रूप में कार्य करते हैं। जीन एक दूसरे के साथ बातचीत करते हैं, और प्रतिलेख उनकी जटिल बातचीत के बाद अंतिम अभिव्यक्ति स्तरों का प्रतिनिधित्व करते हैं। इस तरह के पैटर्न ट्रांसक्रिप्शनल रेगुलेशन नेटवर्क13 और मेटाबॉलिज्म नेटवर्क14, आदि के रूप में तैयार किए जाते हैं। मैसेंजर आरएनए (एमआरएनए) की अभिव्यक्तियों को ट्रांसक्रिप्शन कारकों (टीएफ) और लंबे इंटरजेनिक गैर-कोडिंग आरएनए (लिंसीआरएनए)15,16,17द्वारा ट्रांसक्रिप्शनल रूप से विनियमित किया जा सकता है। पारंपरिक अंतर अभिव्यक्ति विश्लेषण अंतर-सुविधा स्वतंत्रता18,19 की धारणा के साथ इस तरह के जटिल जीन इंटरैक्शन को नजरअंदाज कर दिया।
ग्राफ तंत्रिका नेटवर्क (जीएनएन) में हाल की प्रगति कैंसर अध्ययन20 के लिए ओएमआईसी आधारित डेटा से महत्वपूर्ण जानकारी निकालने में असाधारण क्षमता का प्रदर्शन, उदाहरण के लिए, सह-अभिव्यक्ति मॉड्यूल21 की पहचान करना. जीएनएन की जन्मजात क्षमता उन्हें जीन22,23 के बीच जटिल संबंधों और निर्भरता मॉडलिंग के लिए आदर्श प्रदान करती है।
बायोमेडिकल अध्ययन अक्सर नियंत्रण समूह के खिलाफ एक फेनोटाइप की सटीक भविष्यवाणी करने पर ध्यान केंद्रित करते हैं। इस तरह के कार्यों को आमतौर पर द्विआधारी वर्गीकरण24,25,26 के रूप में तैयार किया जाता है। यहां, दो वर्ग लेबल आम तौर पर 1 और 0, सही और गलत, या यहां तक कि सकारात्मक और नकारात्मक27 के रूप में एन्कोड किए जाते हैं।
इस अध्ययन का उद्देश्य पूर्व-प्रशिक्षित ग्राफ-ध्यान नेटवर्क (GAT) संदर्भ मॉडल के आधार पर एक ट्रांसक्रिप्शनल डेटासेट के ट्रांसक्रिप्शनल रेगुलेशन (mqTrans) दृश्य को उत्पन्न करने के लिए उपयोग में आसान प्रोटोकॉल प्रदान करना है। पहले प्रकाशित कार्य26 से मल्टीटास्क जीएटी फ्रेमवर्क का उपयोग ट्रांसक्रिप्टोमिक सुविधाओं को mqTrans सुविधाओं में बदलने के लिए किया गया था। कैलिफोर्निया विश्वविद्यालय, सांता क्रूज़ (UCSC) Xena प्लेटफ़ॉर्म28 से स्वस्थ ट्रांसक्रिपटोम का एक बड़ा डेटासेट संदर्भ मॉडल (HealthModel) को पूर्व-प्रशिक्षित करने के लिए उपयोग किया गया था, जिसने मात्रात्मक रूप से नियामक कारकों (TFs और lincRNAs) से प्रतिलेखन नियमों को मापा लक्ष्य mRNAs के लिए। उत्पन्न mqTrans दृश्य का उपयोग भविष्यवाणी मॉडल बनाने और अंधेरे बायोमार्कर का पता लगाने के लिए किया जा सकता है। यह प्रोटोकॉल एक उदाहरण उदाहरण के रूप में कैंसर जीनोम एटलस (टीसीजीए) डेटाबेस29 से कोलन एडेनोकार्सिनोमा (सीओएडी) रोगी डेटासेट का उपयोग करता है। इस संदर्भ में, चरण I या II में रोगियों को नकारात्मक नमूने के रूप में वर्गीकृत किया जाता है, जबकि चरण III या IV में सकारात्मक नमूने माने जाते हैं। 26 टीसीजीए कैंसर प्रकारों में अंधेरे और पारंपरिक बायोमार्कर के वितरण की भी तुलना की जाती है।
HealthModel पाइपलाइन का विवरण
इस प्रोटोकॉल में नियोजित पद्धति पहले प्रकाशित ढांचे26 पर आधारित है, जैसा कि चित्र 1में उल्लिखित है। शुरू करने के लिए, उपयोगकर्ताओं को इनपुट डेटासेट तैयार करने, इसे प्रस्तावित हेल्थमॉडल पाइपलाइन में फीड करने और mqTrans सुविधाएँ प्राप्त करने की आवश्यकता होती है। विस्तृत डेटा तैयार करने के निर्देश प्रोटोकॉल अनुभाग की धारा 2 में प्रदान किए जाते हैं। इसके बाद, उपयोगकर्ताओं के पास mqTrans सुविधाओं को मूल ट्रांसक्रिप्टोमिक सुविधाओं के साथ संयोजित करने या केवल उत्पन्न mqTrans सुविधाओं के साथ आगे बढ़ने का विकल्प होता है। उत्पादित डेटासेट को तब एक सुविधा चयन प्रक्रिया के अधीन किया जाता है, जिसमें उपयोगकर्ताओं को वर्गीकरण के लिए k-fold क्रॉस-सत्यापन में k के लिए अपना पसंदीदा मान चुनने की सुविधा होती है। इस प्रोटोकॉल में उपयोग किया जाने वाला प्राथमिक मूल्यांकन मीट्रिक सटीकता है।
हेल्थमॉडल26 ट्रांसक्रिप्टोमिक विशेषताओं को तीन अलग-अलग समूहों में वर्गीकृत करता है: टीएफ (ट्रांसक्रिप्शन फैक्टर), लिनसीआरएनए (लंबी इंटरजेनिक गैर-कोडिंग आरएनए), और एमआरएनए (मैसेंजर आरएनए)। TF सुविधाओं मानव प्रोटीन एटलस30,31 में उपलब्ध एनोटेशन के आधार पर परिभाषित कर रहे हैं. यह कार्य GTEx डेटासेट32 से lincRNAs के एनोटेशन का उपयोग करता है। KEGG डेटाबेस33 में तीसरे स्तर के रास्ते से संबंधित जीन को mRNA सुविधाओं के रूप में माना जाता है। यह ध्यान देने योग्य है कि यदि एक एमआरएनए सुविधा टीआरआरयूटी डेटाबेस34 में प्रलेखित लक्ष्य जीन के लिए नियामक भूमिकाओं को प्रदर्शित करती है, तो इसे टीएफ वर्ग में पुनर्वर्गीकृत किया जाता है।
यह प्रोटोकॉल मैन्युअल रूप से नियामक कारकों (regulatory_geneIDs.csv) और लक्ष्य एमआरएनए (target_geneIDs.csv) के जीन आईडी के लिए दो उदाहरण फाइलें भी उत्पन्न करता है। नियामक सुविधाओं (TFs और lincRNAs) के बीच जोड़ीदार दूरी मैट्रिक्स की गणना पियर्सन सहसंबंध गुणांक द्वारा की जाती है और लोकप्रिय उपकरण भारित जीन सह-अभिव्यक्ति नेटवर्क विश्लेषण (WGCNA)36 (adjacent_matrix.csv) द्वारा क्लस्टर किया जाता है। उपयोगकर्ता ट्रांसक्रिप्टोमिक डेटासेट के mqTrans दृश्य को उत्पन्न करने के लिए इन उदाहरण कॉन्फ़िगरेशन फ़ाइलों के साथ सीधे HealthModel पाइपलाइन का उपयोग कर सकते हैं।
HealthModel के तकनीकी विवरण
हेल्थमॉडल एक ग्राफ के रूप में टीएफ और लिनसीआरएनए के बीच जटिल संबंधों का प्रतिनिधित्व करता है, जिसमें इनपुट फीचर्स वी द्वारा निरूपित कोने के रूप में कार्य करते हैं और ई के रूप में नामित एक इंटर-वर्टेक्स एज मैट्रिक्स है। प्रत्येक नमूने को K नियामक विशेषताओं की विशेषता है, जिसे VK×1 के रूप में दर्शाया गया है। विशेष रूप से, डेटासेट में 425 TFs और 375 lincRNAs शामिल थे, जिसके परिणामस्वरूप K = 425 + 375 = 800 की नमूना आयामीता होती है। एज मैट्रिक्स ई को स्थापित करने के लिए, इस काम ने लोकप्रिय टूल WGCNA35 को नियोजित किया। और , के रूप में 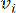
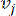 प्रतिनिधित्व किए गए दो शीर्षों को जोड़ने वाले युग्मित वजन पियर्सन सहसंबंध गुणांक द्वारा निर्धारित किया जाता है। जीन नियामक नेटवर्क एक स्केल-फ्री टोपोलॉजी36 प्रदर्शित करता है, जो निर्णायक कार्यात्मक भूमिकाओं के साथ हब जीन की उपस्थिति की विशेषता है। हम दो विशेषताओं या शीर्षों के बीच सहसंबंध की गणना करते हैं, और , टोपोलॉजिकल ओवरलैप माप (टीओएम) का उपयोग निम्नानुसार करते हैं:
प्रतिनिधित्व किए गए दो शीर्षों को जोड़ने वाले युग्मित वजन पियर्सन सहसंबंध गुणांक द्वारा निर्धारित किया जाता है। जीन नियामक नेटवर्क एक स्केल-फ्री टोपोलॉजी36 प्रदर्शित करता है, जो निर्णायक कार्यात्मक भूमिकाओं के साथ हब जीन की उपस्थिति की विशेषता है। हम दो विशेषताओं या शीर्षों के बीच सहसंबंध की गणना करते हैं, और , टोपोलॉजिकल ओवरलैप माप (टीओएम) का उपयोग निम्नानुसार करते हैं:
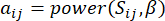 (1)
(1)
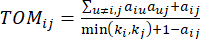 (2)
(2)
सॉफ्ट थ्रेशोल्ड β की गणना WGCNA पैकेज से ‘pickSoft थ्रेशोल्ड’ फ़ंक्शन का उपयोग करके की जाती है। पावर एक्सपोनेंशियल फ़ंक्शन aij लागू किया जाता है, जहां 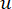 i और j को छोड़कर एक जीन का प्रतिनिधित्व करता है, और
i और j को छोड़कर एक जीन का प्रतिनिधित्व करता है, और 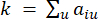 शीर्ष कनेक्टिविटी का प्रतिनिधित्व करता है। डब्ल्यूजीसीएनए आमतौर पर नियोजित असमानता उपाय का उपयोग करके कई मॉड्यूल में ट्रांसक्रिप्टोमिक सुविधाओं की अभिव्यक्ति प्रोफाइल को क्लस्टर करता है (
शीर्ष कनेक्टिविटी का प्रतिनिधित्व करता है। डब्ल्यूजीसीएनए आमतौर पर नियोजित असमानता उपाय का उपयोग करके कई मॉड्यूल में ट्रांसक्रिप्टोमिक सुविधाओं की अभिव्यक्ति प्रोफाइल को क्लस्टर करता है (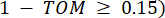 37.
37.
HealthModel ढांचे मूल रूप से एक multitask सीखने वास्तुकला26 के रूप में डिजाइन किया गया था. यह प्रोटोकॉल केवल ट्रांसक्रिप्टोमिक mqTrans दृश्य के निर्माण के लिए मॉडल पूर्व-प्रशिक्षण कार्य का उपयोग करता है। उपयोगकर्ता अतिरिक्त कार्य-विशिष्ट ट्रांसक्रिप्टोमिक नमूनों के साथ मल्टीटास्क ग्राफ ध्यान नेटवर्क के तहत पूर्व-प्रशिक्षित हेल्थमॉडल को और परिष्कृत करना चुन सकता है।
सुविधा चयन और वर्गीकरण के तकनीकी विवरण
सुविधा चयन पूल ग्यारह सुविधा चयन (एफएस) एल्गोरिदम लागू करता है। उनमें से, तीन फ़िल्टर-आधारित FS एल्गोरिदम हैं: अधिकतम सूचना गुणांक (SK_mic) का उपयोग करके K सर्वोत्तम सुविधाओं का चयन करना, MIC (SK_fpr) के FPR के आधार पर K सुविधाओं का चयन करना, और MIC (SK_fdr) की उच्चतम झूठी खोज दर के साथ K सुविधाओं का चयन करना। इसके अतिरिक्त, तीन पेड़-आधारित एफएस एल्गोरिदम गिनी इंडेक्स (DT_gini), अनुकूली बूस्टेड निर्णय पेड़ (एडाबूस्ट), और यादृच्छिक वन (RF_fs) के साथ एक निर्णय पेड़ का उपयोग करके व्यक्तिगत विशेषताओं का आकलन करते हैं। पूल में दो रैपर विधियां भी शामिल हैं: रैखिक समर्थन वेक्टर क्लासिफायरियर (RFE_SVC) के साथ रिकर्सिव फीचर एलिमिनेशन और लॉजिस्टिक रिग्रेशन क्लासिफायरियर (RFE_LR) के साथ रिकर्सिव फीचर एलिमिनेशन। अंत में, दो एम्बेडिंग एल्गोरिदम शामिल हैं: शीर्ष क्रम के L1 फीचर महत्व मूल्यों (lSVC_L1) के साथ रैखिक SVC क्लासिफायरियर और शीर्ष क्रम के L1 फीचर महत्व मूल्यों (LR_L1) के साथ लॉजिस्टिक रिग्रेशन क्लासिफायरियर।
क्लासिफायरियर पूल वर्गीकरण मॉडल बनाने के लिए सात अलग-अलग क्लासिफायर को नियुक्त करता है। इन क्लासिफायरों में रैखिक समर्थन वेक्टर मशीन (SVC), गाऊसी Naïve Bayes (GNB), लॉजिस्टिक रिग्रेशन क्लासिफायरियर (LR), k-निकटतम पड़ोसी, k डिफ़ॉल्ट रूप से 5 पर सेट (KNN), XGBoost, यादृच्छिक वन (RF), और निर्णय वृक्ष (DT) शामिल हैं।
ट्रेन में डेटासेट का यादृच्छिक विभाजन: परीक्षण सबसेट कमांड लाइन में सेट किया जा सकता है। प्रदर्शित उदाहरण ट्रेन के अनुपात का उपयोग करता है: परीक्षण = 8: 2।
