Lipide nanodeeltjes (LNP) formuleringen voor in vivo genafgiftesystemen omvatten over het algemeen vier samenstellende lipiden uit de categorieën ioniseerbare, helper- en PEG-lipiden 1,2,3. Of deze lipiden nu alleen of gelijktijdig met andere niet-mengselfactoren worden bestudeerd, experimenten voor deze formuleringen vereisen “mengsel” -ontwerpen omdat – gegeven een kandidaat-formulering – het verhogen of verlagen van de verhouding van een van de lipiden noodzakelijkerwijs leidt tot een overeenkomstige afname of toename van de som van de verhoudingen van de andere drie lipiden.
Ter illustratie wordt verondersteld dat we een LNP-formulering optimaliseren die momenteel een vast recept gebruikt dat als benchmark zal worden behandeld. Het doel is om de potentie van de LNP te maximaliseren en tegelijkertijd de gemiddelde deeltjesgrootte te minimaliseren. De studiefactoren die in het experiment worden gevarieerd, zijn de molaire verhoudingen van de vier samenstellende lipiden (ioniseerbaar, cholesterol, DOPE, PEG), de N: P-verhouding, de stroomsnelheid en het ioniseerbare lipidetype. De ioniseerbare en helperlipiden (inclusief cholesterol) mogen variëren over een breder bereik van molaire verhouding, 10-60%, dan PEG, die in deze illustratie zal variëren van 1-5%. Het referentieformuleringsrecept en de bereiken van de andere factoren en hun afrondingsgranulariteit worden gespecificeerd in aanvullend dossier 1. Voor dit voorbeeld zijn de wetenschappers in staat om 23 runs (unieke batches deeltjes) op één dag uit te voeren en willen dat als hun steekproefgrootte gebruiken als deze aan de minimumvereisten voldoet. Gesimuleerde resultaten voor dit experiment zijn opgenomen in Aanvullend Dossier 2 en Aanvullend Dossier 3.
Rampado en Peer4 hebben een recent overzichtsartikel gepubliceerd over het onderwerp van ontworpen experimenten voor de optimalisatie van op nanodeeltjes gebaseerde medicijnafgiftesystemen. Kauffman et al.5 beschouwden LNP-optimalisatiestudies met behulp van fractionele factoriële en definitieve screeningsontwerpen6; Dit soort ontwerpen kan echter geen mengselbeperking opvangen zonder toevlucht te nemen tot het gebruik van inefficiënte “spelingsvariabelen”7 en worden meestal niet gebruikt wanneer mengselfactoren aanwezig zijn 7,8. In plaats daarvan worden “optimale ontwerpen” die in staat zijn om een mengselbeperking op te nemen, traditioneel gebruikt voor experimenten met mengselprocessen9. Deze ontwerpen richten zich op een door de gebruiker gespecificeerde functie van de studiefactoren en zijn alleen optimaal (in een van een aantal mogelijke betekenissen) als deze functie de ware relatie tussen de studiefactoren en responsen vastlegt. Merk op dat er in de tekst een onderscheid is tussen “optimale ontwerpen” en “optimale formuleringskandidaten”, waarbij de laatste verwijst naar de beste formuleringen die door een statistisch model worden geïdentificeerd. Optimale ontwerpen hebben drie belangrijke nadelen voor experimenten met mengselprocessen. Ten eerste, als de wetenschapper niet anticipeert op een interactie van de studiefactoren bij het specificeren van het doelmodel, dan zal het resulterende model bevooroordeeld zijn en inferieure kandidaatformuleringen kunnen produceren. Ten tweede plaatsen optimale ontwerpen de meeste runs op de buitengrens van de factorruimte. In LNP-studies kan dit leiden tot een groot aantal verloren runs als de deeltjes zich niet correct vormen aan uitersten van de lipide- of procesinstellingen. Ten derde geven wetenschappers vaak de voorkeur aan experimentele runs op het binnenste van de factorruimte om een modelonafhankelijk gevoel van het responsoppervlak te krijgen en het proces direct te observeren in voorheen onontgonnen gebieden van de factorruimte.
Een alternatief ontwerpprincipe is om te streven naar een geschatte uniforme dekking van de (mengselbeperkte) factorruimte met een ruimtevullend ontwerp10. Deze ontwerpen offeren enige experimentele efficiëntie op ten opzichte van optimale ontwerpen9 (ervan uitgaande dat de hele factorruimte leidt tot geldige formuleringen), maar bieden verschillende voordelen in een afweging die nuttig zijn in deze toepassing. Het ruimtevullende ontwerp maakt geen a priori aannames over de structuur van het responsoppervlak; Dit geeft het de flexibiliteit om onverwachte relaties tussen de studiefactoren vast te leggen. Dit stroomlijnt ook de ontwerpgeneratie omdat het niet nodig is om beslissingen te nemen over welke regressietermen moeten worden toegevoegd of verwijderd als de gewenste rungrootte wordt aangepast. Wanneer sommige ontwerppunten (recepten) leiden tot mislukte formuleringen, maken ruimtevullende ontwerpen het mogelijk om de faalgrens over de studiefactoren te modelleren, terwijl ook statistische modellen voor de studieresponsen over de succesvolle factorcombinaties worden ondersteund. Ten slotte maakt de binnendekking van de factorruimte modelonafhankelijke grafische verkenning van het responsoppervlak mogelijk.
Om de mengselfactorsubruimte van een mengselprocesexperiment te visualiseren, worden gespecialiseerde driehoekige “ternaire percelen” gebruikt. Figuur 1 motiveert dit gebruik: in de kubus van punten waar drie ingrediënten elk van 0 tot 1 mogen variëren, worden de punten die voldoen aan een beperking dat de som van de ingrediënten gelijk is aan 1 rood gemarkeerd. De mengselbeperking op de drie ingrediënten reduceert de haalbare factorruimte tot een driehoek. In LNP-toepassingen met vier mengselingrediënten produceren we zes verschillende ternaire plots om de factorruimte weer te geven door twee lipiden tegelijk uit te zetten tegen een “Anderen” -as die de som van de andere lipiden vertegenwoordigt.
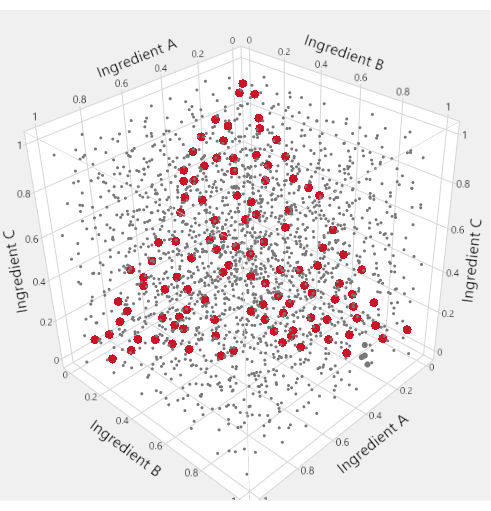
Figuur 1: Driehoeksfactorgebieden. In de ruimtevullende plot in de kubus vertegenwoordigen de kleine grijze stippen formuleringen die niet consistent zijn met de mengselbeperking. De grotere rode punten liggen op een driehoek die in de kubus is ingeschreven en vertegenwoordigen formuleringen waarvoor aan de mengselbeperking is voldaan. Klik hier om een grotere versie van deze figuur te bekijken.
Naast de lipidemengselfactoren zijn er vaak een of meer continue procesfactoren zoals N:P-verhouding, bufferconcentratie of stroomsnelheid. Categorische factoren kunnen aanwezig zijn, zoals ioniseerbaar lipidentype, helperlipidentype of buffertype. Het doel is om een formulering te vinden (een mengsel van lipiden en instellingen voor procesfactoren) die een zekere mate van potentie maximaliseert en / of fysiochemische kenmerken verbetert, zoals het minimaliseren van deeltjesgrootte en PDI (polydispersiteitsindex), het maximaliseren van procentuele inkapseling en het minimaliseren van bijwerkingen – zoals gewichtsverlies – in in vivo studies. Zelfs wanneer wordt uitgegaan van een redelijk benchmarkrecept, kan er interesse zijn in heroptimalisatie gezien een verandering in de genetische lading of bij het overwegen van veranderingen in de procesfactoren of lipidetypen.
Cornell7 biedt een definitieve tekst over de statistische aspecten van mengsel- en mengselprocesexperimenten, waarbij Myers et al.9 een uitstekende samenvatting geven van de meest relevante mengselontwerp- en analyseonderwerpen voor optimalisatie. Deze werken kunnen wetenschappers echter overladen met statistische details en met gespecialiseerde terminologie. Moderne software voor het ontwerpen en analyseren van experimenten biedt een robuuste oplossing die de meeste LNP-optimalisatieproblemen voldoende ondersteunt zonder een beroep te hoeven doen op de relevante theorie. Hoewel meer gecompliceerde of prioritaire studies nog steeds baat zullen hebben bij samenwerking met een statisticus en optimale in plaats van ruimtevullende ontwerpen kunnen gebruiken, is ons doel om het comfortniveau van wetenschappers te verbeteren en optimalisatie van LNP-formuleringen aan te moedigen zonder een beroep te doen op inefficiënte one-factor-at-a-time (OFAT) testen11 of gewoon genoegen te nemen met de eerste formulering die voldoet aan de specificaties.
In dit artikel wordt een workflow gepresenteerd die statistische software gebruikt om een generiek LNP-formuleringsprobleem te optimaliseren, waarbij ontwerp- en analyseproblemen worden aangepakt in de volgorde waarin ze zullen worden aangetroffen. In feite zal de methode werken voor algemene optimalisatieproblemen en is niet beperkt tot LNP’s. Onderweg worden verschillende veelgestelde vragen die zich voordoen behandeld en worden aanbevelingen gedaan die zijn gebaseerd op ervaring en op simulatieresultaten12. Het recent ontwikkelde raamwerk van zelfgevalideerde ensemblemodellen (SVEM)13 heeft de anders fragiele benadering van het analyseren van resultaten van mengselprocesexperimenten sterk verbeterd, en we gebruiken deze aanpak om een vereenvoudigde strategie voor formuleringsoptimalisatie te bieden. Hoewel de workflow is opgebouwd op een algemene manier die kan worden gevolgd met behulp van andere softwarepakketten, is JMP 17 Pro uniek in het aanbieden van SVEM samen met de grafische samenvattingstools die we nodig hebben gevonden om de anders geheimzinnige analyse van mengselprocesexperimenten te vereenvoudigen. Als gevolg hiervan zijn JMP-specifieke instructies ook opgenomen in het protocol.
SVEM maakt gebruik van dezelfde lineaire regressiemodelbasis als de traditionele benadering, maar het stelt ons in staat om vervelende wijzigingen te voorkomen die nodig zijn om een “volledig model” van kandidaat-effecten te passen door een voorwaartse selectie of een bestrafte selectie (Lasso) basisbenadering te gebruiken. Bovendien biedt SVEM een verbeterde “gereduceerde model” -pasvorm die het potentieel voor het opnemen van ruis (proces plus analytische variantie) die in de gegevens wordt weergegeven, minimaliseert. Het werkt door het gemiddelde te nemen van de voorspelde modellen die het resultaat zijn van het herhaaldelijk herwegen van het relatieve belang van elke run in het model 13,14,15,16,17,18. SVEM biedt een raamwerk voor het modelleren van mengselprocesexperimenten dat zowel gemakkelijker te implementeren is als traditionele single-shot regressie en betere kwaliteit optimale formuleringskandidaten oplevert12,13. De wiskundige details van SVEM vallen buiten het bestek van dit artikel en zelfs een vluchtige samenvatting buiten het relevante literatuuronderzoek zou afleiden van het belangrijkste voordeel in deze toepassing: het maakt een eenvoudige, robuuste en nauwkeurige klik-en-klaar-procedure voor beoefenaars mogelijk.
De gepresenteerde workflow is consistent met de Quality by Design (QbD)19-benadering van farmaceutische ontwikkeling20. Het resultaat van de studie zal een goed begrip zijn van de functionele relatie die de materiaalattributen en procesparameters koppelt aan kritische kwaliteitsattributen (CQAs)21. Daniel et al.22 bespreken het gebruik van een QbD-framework specifiek voor RNA-platformproductie: onze workflow kan binnen dit kader als hulpmiddel worden gebruikt.
