测序和基因分型的基础研究,包括全基因组关联分析(GWAS),候选人基因研究和深测序研究,已经确定了在统计学上与疾病,性状或表型相关的许多基因变异。相反早期预测,大多数这些变体(85-93%)的分布在非编码区,并且不改变蛋白质1,2的氨基酸序列。解释这些非编码变体的功能和确定它们连接到相关的疾病的生物学机制,特征,或表型已被证明具有挑战性3-6。我们已开发,以确定链接变体的重要中间体的表型的分子机制的一般策略 – 基因表达。这条管线是专门设计来确定的TF由遗传变异体结合的调制。这一策略结合的目的是预测的计算方法和分子生物学技术在硅片的候选变体的生物学效应,并验证这些预测凭经验( 图1)。
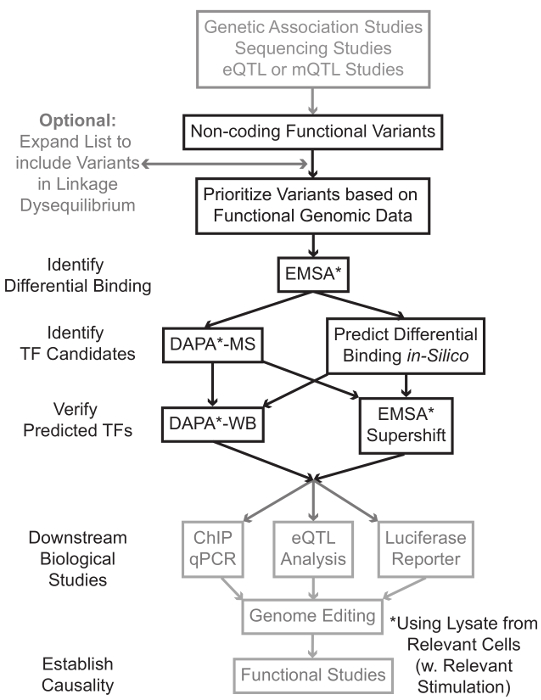
图1: 对于不包含在这个手稿以灰色阴影相关的详细协议的非编码基因变异步骤的分析战略方针 请点击此处查看该图的放大版本。
在许多情况下,通过扩大变体的列表以包括与每个统计学关联变体在高联动不平衡(LD)的所有那些开始是很重要的。 LD是在两个不同的染色体位置的等位基因的非随机关联,可以由R 2统计7被测量的量度。 R 2是林的措施卡格两个变量之间的不平衡,有两个变量之间的R 2 = 1表示完全连锁。在高LD等位基因被发现在整个人群祖先染色体上共分离。当前的基因分型阵列不包括在人类基因组中所有已知的变体。相反,他们利用了人类基因组中的LD和包括公知的变体作为代理为LD 8的一特定区域内的其它变体的一个子集。因此,在没有任何生物后果的变体可以与特定疾病,因为它是在与一个有意义的生物效应的因果变体的变体的LD相关联。在程序上,建议转换的1000基因组最新发布的项目9项变量调用文件(VCF)与PLINK 10,11,用于全基因组关联分析的开放源代码工具兼容的二进制文件。随后,LD R 2> 0.8所有其他遗传变异与每个输入遗传VAriant可确定为候选者。使用合适的参考人群该步进例如是很重要的,如果一个变种是在欧洲血统的科目,从类似的血统科目的数据应该用于LD扩展标识。
LD膨胀常常导致数十个候选变体,它是可能的,只有这些一小部分有助于疾病的机制。通常,它是不可行的实验逐一检查每个这些变体。因此,有用以利用数千公开可用功能基因组数据集作为过滤器的变体的优先次序。例如,编码财团12已经如DNA酶SEQ 13,ATAC进行数千描述转录因子的结合芯片起实验和辅因子,以及组蛋白标记在各种上下文,以及染色质辅助数据从技术-SEQ 14和FAIRE-SEQ 15。数据BASES和Web服务器如UCSC基因组浏览器16,路线图表观基因组17,蓝图表观基因组18,顺反组19,并重新映射20提供由这些和其他实验技术在广泛的细胞类型和条件产生的数据免费访问。当有太多的变体通过实验检验,这些数据可以被用来优先那些位于相关的细胞和组织类型的可能调控区之内。此外,在一个变型为特定蛋白的芯片起峰内的情况下,这些数据可以提供潜在线索作为对特定TF(S)或辅因子的结合可能影响。
接着,将所得的优先变体实验筛选,以验证预测的基因型依赖性蛋白使用EMSA 21,22结合。 EMSA测量的寡核苷酸上的非还原性TBE凝胶迁移的变化。荧光标记的寡核苷酸温育与核裂解物,以及核因子的结合将延缓在凝胶上的寡的运动。以这种方式,已经结合更多的核因子将呈现为对扫描更强的荧光信号寡。值得注意的是,EMSA不需要关于特定蛋白质的结合会受到影响的预测。
一旦变体被识别,它们位于预测的调节区之内,并且能够差动结合核因子中,采用计算的方法来预测具体TF(S),其结合它们可能会影响。我们优选使用CIS-BP 23,24,RegulomeDB 25,UniProbe 26和JASPAR 27。一旦候选人转录因子被确定,这些预测可以专门使用抗转录因子这些(EMSA-supershifts和DAPA-西部片)测试。一个EMSA-超迁移涉及增加了一个特定的TF-抗体与核裂解物和寡。阳性结果在EMSA-超迁移是再版esented如在EMSA频带的进一步转变,或带的损耗(在参考28中综述)。在互补DAPA,含有该变体和20个碱基对的侧翼核苷酸的5'-生物素化的寡核苷酸双链体与来自相关的细胞类型(多个)核裂解物温育以捕获任何核因子特异性结合的寡核苷酸。低聚双链核因子复合物是通过在一个磁列链霉微珠固定。结合的核因子直接通过洗脱29,48收集。结合预测可以然后通过使用特异于所述蛋白质的抗体的Western印迹来评估。在没有明显的预测,或过多的预测,从DAPA实验的变体拉起伏的洗脱可被发送到一个蛋白质组学芯使用质谱来识别候选转录因子的情况下,其可以随后使用验证这些先前描述的方法。
在该articl剩余即,提供了一种用于遗传变异体的EMSA和DAPA分析的详细协议。
