Le calcul de l’ADN utilise un ensemble d’oligonucléotides conçus comme support de calcul. Ces oligonucléotides sont programmés avec des séquences pour s’assembler dynamiquement selon la logique spécifiée par l’utilisateur et répondre à des entrées d’acide nucléique spécifiques. Dans les études de preuve de concept, le résultat du calcul consiste généralement en un ensemble d’oligonucléotides marqués par fluorescence qui peuvent être détectés par électrophorèse sur gel ou lecteurs de plaques de fluorescence. Au cours des 30 dernières années, des circuits de calcul de l’ADN de plus en plus complexes ont été démontrés, tels que diverses cascades logiques numériques, des réseaux de réactions chimiques et des réseaux de neurones1,2,3. Pour aider à la préparation de ces circuits d’ADN, des modèles mathématiques ont été utilisés pour prédire la fonctionnalité des circuits de gènes synthétiques4,5, et des outils informatiques ont été développés pour la conception de séquences d’ADN orthogonales6,7,8,9,10 . Par rapport aux ordinateurs à base de silicium, les avantages des ordinateurs à ADN comprennent leur capacité à s’interfacer directement avec les biomolécules, à fonctionner en solution en l’absence d’alimentation électrique, ainsi que leur compacité et leur stabilité globales. Avec l’avènement du séquençage de nouvelle génération, le coût de la synthèse des ordinateurs à ADN a diminué au cours des deux dernières décennies à un rythme plus rapide que la loi de Moore11. Des applications de ces ordinateurs basés sur l’ADN commencent maintenant à émerger, telles que pour le diagnostic des maladies12,13, pour alimenter la biophysique moléculaire14, et comme plates-formes de stockage de données15.

Figure 1: Mécanisme de déplacement des brins d’ADN médiés par les orteils. L’orteil, δ, est une séquence libre et non liée sur un duplex partiel. Lorsqu’un domaine complémentaire (δ*) est introduit sur un deuxième brin, le domaine δ libre sert de base pour l’hybridation, permettant au reste du brin (ɑ*) de déplacer lentement son concurrent par une réaction réversible de zipping/décompression connue sous le nom de migration de brin. À mesure que la longueur de δ augmente, le ΔG de la réaction vers l’avant diminue et le déplacement se produit plus facilement. Veuillez cliquer ici pour voir une version agrandie de cette figure.
À ce jour, la majorité des ordinateurs à ADN utilisent un motif bien établi dans le domaine de la nanotechnologie dynamique de l’ADN connu sous le nom de déplacement de brin d’ADN médié par les orteils (TMDSD, Figure 1)16. Ce motif est constitué d’un duplex d’ADN partiellement double brin (dsDNA) affichant de courts surplombs « toehold » (c’est-à-dire 7 à 10 nucléotides (nt)). Les brins d’entrée d’acide nucléique peuvent interagir avec les duplex partiels à travers l’orteil. Cela conduit au déplacement de l’un des brins du duplex partiel, et ce brin libéré peut alors servir d’entrée pour les duplex partiels en aval. Ainsi, TMDSD permet la cascade du signal et le traitement de l’information. En principe, les motifs tmDSD orthogonaux peuvent fonctionner indépendamment dans la solution, ce qui permet un traitement parallèle de l’information. Il y a eu un certain nombre de variations sur la réaction TMDSD, telles que l’échange de brins d’ADN médié par la toehold (TMDSE)17,les orteils « sans fuite » avec des domaines doubles longs18,les orteils dépareillés par séquence19et le déplacement de brin médié par la « poignée »20. Ces principes de conception innovants permettent une énergie et une dynamique TMDSD plus finement ajustées pour améliorer les performances de calcul de l’ADN.
Les circuits de gènes synthétiques, tels que les circuits de gènes transcriptionnels, sont également capables de calculer21,22,23. Ces circuits sont régulés par des facteurs de transcription des protéines, qui activent ou répriment la transcription d’un gène en se liant à des éléments d’ADN régulateurs spécifiques. Par rapport aux circuits à base d’ADN, les circuits transcriptionnels présentent plusieurs avantages. Premièrement, la transcription enzymatique a un taux de rotation beaucoup plus élevé que les circuits d’ADN catalytiques existants, générant ainsi plus de copies de sortie par copie unique d’entrée et fournissant un moyen plus efficace d’amplification du signal. En outre, les circuits transcriptionnels peuvent produire différentes molécules fonctionnelles, telles que des aptamères ou des ARN messagers (ARNm) codant pour des protéines thérapeutiques, en tant que sorties de calcul, qui peuvent être exploitées pour différentes applications. Cependant, une limitation majeure des circuits transcriptionnels actuels est leur manque d’évolutivité. En effet, il existe un ensemble très limité de facteurs de transcription basés sur des protéines orthogonales, et la conception de novo de nouveaux facteurs de transcription protéique reste techniquement difficile et prend beaucoup de temps.
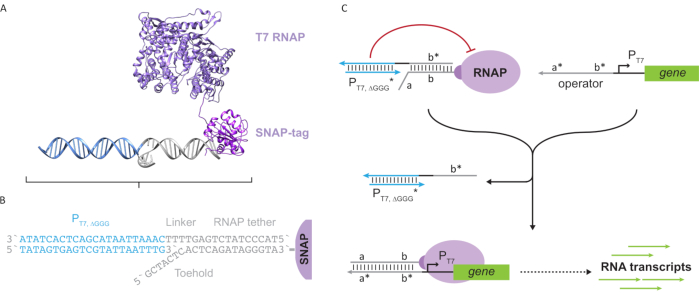
Figure 2: Abstraction et mécanisme du complexe de polymérase « attache » et « cage ». (A et B) Une téther oligonucléotidique est marquée enzymatiquement en une polymérase T7 par la réaction SNAP-tag. Une cage constituée d’un « faux » promoteur T7 avec un porte-à-faux attache-complément lui permet de s’hybrider à l’attache et de bloquer l’activité transcriptionnelle. (C) Lorsque l’opérateur (a*b*) est présent, il se lie à l’orteil sur l’attache oligonucléotidique (ab) et déplace la région b* de la cage, permettant la transcription. Cette figure a été modifiée à partir de Chou et Shih27. Abréviations : RNAP = ARN polymérase. Veuillez cliquer ici pour voir une version agrandie de cette figure.
Cet article présente un nouveau bloc de construction pour l’informatique moléculaire qui combine les fonctionnalités des circuits transcriptionnels avec l’évolutivité des circuits à base d’ADN. Ce bloc de construction est un RNAP T7 attaché de manière covalente avec une attache d’ADN simple brin(Figure 2A). Pour synthétiser ce RNAP T7 attaché à l’ADN, la polymérase a été fusionnée à un marqueur SNAP N-terminal24 et exprimée de manière recombinante dans Escherichia coli. Le SNAP-tag a ensuite réagi avec un oligonucléotide fonctionnalisé avec le substrat BG. L’attache oligonucléotidique permet le positionnement d’invités moléculaires à proximité de la polymérase via l’hybridation de l’ADN. L’un de ces invités était un bloqueur transcriptionnel compétitif appelé « cage », qui consiste en un « faux » duplex d’ADN promoteur T7 sans gène en aval(Figure 2B). Lorsqu’elle est liée à l’ARNP via son attache oligonucléotidique, la cage bloque l’activité de la polymérase en surpassant les autres modèles d’ADN pour la liaison À l’ARNP, rendant l’ARNP dans un état « OFF »(Figure 2C).
Pour activer la polymérase à un état « ON », des modèles d’ADN T7 avec des domaines « opérateurs » monocaténaires en amont du promoteur T7 du gène ont été conçus. Le domaine de l’opérateur (c’est-à-dire le domaine a*b* Figure 2C) peut être conçu pour déplacer la cage de l’ARNP via TMDSD et positionner le RNAP proximal au promoteur T7 du gène, initiant ainsi la transcription. Alternativement, des modèles d’ADN ont également été conçus lorsque la séquence de l’opérateur était complémentaire aux brins auxiliaires d’acide nucléique appelés « facteurs de transcription artificiels » (c.-à-d. les brins TFA et TFB à la figure 3A). Lorsque les deux brins sont introduits dans la réaction, ils s’assemblent sur le site de l’opérateur, créant un nouveau domaine pseudo-contigu a*b*. Ce domaine peut ensuite déplacer la cage via TMDSD pour initier la transcription(Figure 3B). Ces brins peuvent être fournis de manière exogène ou produits.
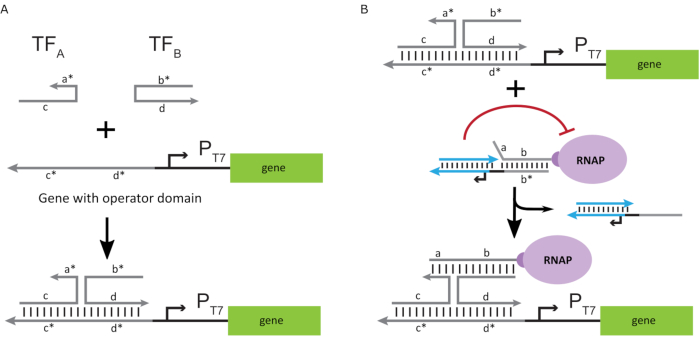
Figure 3: Programmation sélective de l’activité de la polymérase à l’aide d’un activateur de commutation à trois composants. (A) Lorsque les facteurs de transcription (TFA et TFB)sont présents, ils se lient au domaine opérateur en amont du promoteur, formant une pseudo séquence monocaténaire (a*b*)capable de déplacer la cage par déplacement d’ADN médié par l’orteil. (B) Ce domaine a*b* peut déplacer la cage via TMDSD pour initier la transcription. Cette figure a été modifiée à partir de Chou et Shih27. Abréviations : TF = facteur de transcription ; RNAP = ARN polymérase; TMDSD = déplacement de brin d’ADN médié par les orteils. Veuillez cliquer ici pour voir une version agrandie de cette figure.
L’utilisation de facteurs de transcription à base d’acides nucléiques pour la régulation transcriptionnelle in vitro permet la mise en œuvre évolutive de comportements de circuit sophistiqués tels que la logique numérique, la rétroaction et la cascade de signaux. Par exemple, on peut construire des cascades de portes logiques en concevant des séquences d’acides nucléiques telles que les transcriptions d’un gène en amont activent un gène en aval. Une application qui exploite la cascade et le multiplexage rendus possibles par cette technologie proposée est le développement de circuits informatiques moléculaires plus sophistiqués pour le diagnostic portable et le traitement des données moléculaires. En outre, l’intégration des capacités de calcul moléculaire et de synthèse d’ARN de novo peut permettre de nouvelles applications. Par exemple, un circuit moléculaire peut être conçu pour détecter un ou une combinaison d’ARN définis par l’utilisateur en tant qu’ENTRÉES ET SORTIES D’ARN thérapeutiques ou d’ARNm codant pour des peptides ou des protéines fonctionnels pour des applications médicales au point de service.
