DNA-Computing verwendet eine Reihe von entworfenen Oligonukleotiden als Medium für die Berechnung. Diese Oligonukleotide sind mit Sequenzen programmiert, die sich dynamisch nach einer benutzerdefinierten Logik zusammensetzen und auf spezifische Nukleinsäureeinträge reagieren. In Proof-of-Concept-Studien besteht die Ausgabe der Berechnung typischerweise aus einem Satz fluoreszierend markierter Oligonukleotide, die über Gelelektrophorese oder Fluoreszenzplattenleser nachgewiesen werden können. In den letzten 30 Jahren wurden immer komplexere DNA-Rechenschaltungen demonstriert, wie verschiedene digitale Logikkaskaden, chemische Reaktionsnetzwerke und neuronale Netze1,2,3. Um die Herstellung dieser DNA-Schaltkreise zu unterstützen, wurden mathematische Modelle verwendet, um die Funktionalität der synthetischen Genschaltkreise4,5vorherzusagen, und Berechnungswerkzeuge wurden für das orthogonale DNA-Sequenzdesign entwickelt6,7,8,9,10 . Im Vergleich zu siliziumbasierten Computern gehören zu den Vorteilen von DNA-Computern ihre Fähigkeit, direkt mit Biomolekülen zu verbinden, in Lösung zu arbeiten, wenn keine Stromversorgung vorhanden ist, sowie ihre allgemeine Kompaktheit und Stabilität. Mit dem Aufkommen der Next-Generation-Sequenzierung sind die Kosten für die Synthese von DNA-Computern in den letzten zwei Jahrzehnten schneller gesunken als das Mooresche Gesetz11. Anwendungen solcher DNA-basierten Computer beginnen sich nun zu entwickeln, wie z.B. für die Krankheitsdiagnose12,13, für die Stromversorgung der molekularen Biophysik14und als Datenspeicherplattformen15.

Abbildung 1: Mechanismus der Zehengriff-vermittelten DNA-Strangverschiebung. Der Toehold, δ, ist eine freie, ungebundene Sequenz auf einem Teilduplex. Wenn eine komplementäre Domäne (δ*) auf einem zweiten Strang eingeführt wird, dient die freie δ Domäne als Haltepunkt für die Hybridisierung, so dass der Rest des Strangs (ɑ*) seinen Konkurrenten durch eine reversible Reaktion, die als Strangmigration bezeichnet wird, langsam verdrängen kann. Wenn die Länge δ zunimmt, nimmt das ΔG für die Vorwärtsreaktion ab und die Verschiebung erfolgt leichter. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
Bis heute verwendet die Mehrheit der DNA-Computer ein etabliertes Motiv auf dem Gebiet der dynamischen DNA-Nanotechnologie, das als Zehengriff-vermittelte DNA-Strangverschiebung (TMDSD, Abbildung 1)16bekannt ist. Dieses Motiv besteht aus einem teilweise doppelsträngigen DNA-Duplex (dsDNA), der kurze “Zehenhalte”-Überhänge (d.h. 7- bis 10 Nukleotide (nt)) aufweist. Nukleinsäure-“Eingangsstränge” können mit den Teilduplexen durch den Zehengriff interagieren. Dies führt zur Verschiebung eines der Stränge aus dem Teilduplex, und dieser freigesetzte Strang kann dann als Eingang für nachgeschaltete Teilduplexe dienen. Somit ermöglicht TMDSD die Signalkaskadierung und Informationsverarbeitung. Prinzipiell können orthogonale TMDSD-Motive in Lösung eigenständig arbeiten und ermöglichen so eine parallele Informationsverarbeitung. Es gab eine Reihe von Variationen der TMDSD-Reaktion, wie z.B. Toehold-vermittelter DNA-Strangaustausch (TMDSE)17, “lecklose” Zehengriffe mit doppelt langen Domänen18, sequenz-mismatched Zehenhalte19und “Handhold”-vermittelte Strangverschiebung20. Diese innovativen Designprinzipien ermöglichen eine feiner abgestimmte TMDSD-Energetik und -Dynamik zur Verbesserung der DNA-Rechenleistung.
Synthetische Genschaltkreise, wie transkriptionelle Genschaltkreise, sind ebenfalls in der Lage,21,22,23zu berechnen. Diese Schaltkreise werden durch Proteintranskriptionsfaktoren reguliert, die die Transkription eines Gens durch Bindung an bestimmte regulatorische DNA-Elemente aktivieren oder unterdrücken. Im Vergleich zu DNA-basierten Schaltkreisen haben Transkriptionsschaltkreise mehrere Vorteile. Erstens hat die enzymatische Transkription eine viel höhere Fluktuationsrate als bestehende katalytische DNA-Schaltkreise, wodurch mehr Kopien der Ausgabe pro einzelner Kopie der Eingabe erzeugt werden und ein effizienteres Mittel zur Signalverstärkung bereitgestellt wird. Darüber hinaus können Transkriptionsschaltkreise verschiedene funktionelle Moleküle wie Aptamere oder Boten-RNA (mRNA), die für therapeutische Proteine kodieren, als Rechenergebnisse erzeugen, die für verschiedene Anwendungen genutzt werden können. Eine wesentliche Einschränkung der aktuellen Transkriptionsschaltungen ist jedoch ihre mangelnde Skalierbarkeit. Dies liegt daran, dass es nur eine sehr begrenzte Anzahl orthogonaler Protein-basierter Transkriptionsfaktoren gibt und das De-novo-Design neuer Proteintranskriptionsfaktoren technisch anspruchsvoll und zeitaufwendig bleibt.
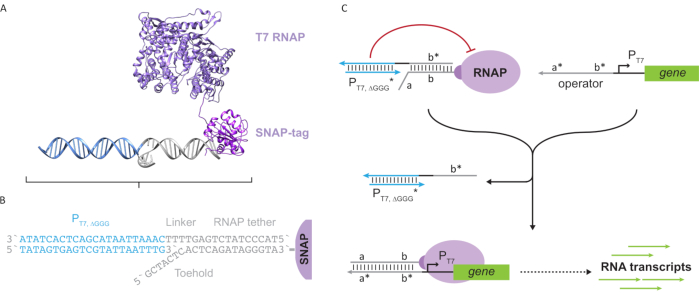
Abbildung 2: Abstraktion und Mechanismus des “Tether”- und “Cage”-Polymerase-Komplexes. (A und B) Ein Oligonukleotid-Tether wird enzymatisch durch die SNAP-Tag-Reaktion zu einer T7-Polymerase markiert. Ein Käfig, der aus einem “künstlichen” T7-Promotor mit einem Tether-Komplement-Überhang besteht, ermöglicht es, mit dem Tether zu hybridisieren und die Transkriptionsaktivität zu blockieren. (C) Wenn der Operator (a*b*) vorhanden ist, bindet er an den Haltepunkt des Oligonukleotid-Tethers (ab) und verschiebt den b*-Bereich des Käfigs, wodurch eine Transkription stattfinden kann. Diese Figur wurde von Chou und Shih27modifiziert. Abkürzungen: RNAP = RNA-Polymerase. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
Dieses Papier stellt einen neuartigen Baustein für molekulares Rechnen vor, der die Funktionalitäten von Transkriptionsschaltkreisen mit der Skalierbarkeit von DNA-basierten Schaltkreisen kombiniert. Dieser Baustein ist ein T7 RNAP kovalent gebunden mit einem einzelsträngigen DNA-Tether (Abbildung 2A). Um dieses DNA-tethered T7 RNAP zu synthetisieren, wurde die Polymerase zu einem N-terminalen SNAP-Tag24 fusioniert und rekombinant in Escherichia coliexprimiert. Der SNAP-Tag wurde dann mit einem Oligonukleotid umgesetzt, das mit dem BG-Substrat funktionalisiert wurde. Das Oligonukleotid-Tether ermöglicht die Positionierung molekularer Gäste in unmittelbarer Nähe zur Polymerase mittels DNA-Hybridisierung. Einer dieser Gäste war ein kompetitiver Transkriptionsblocker, der als “Käfig” bezeichnet wird und aus einem “künstlichen” T7-Promotor-DNA-Duplex ohne nachgeschaltetes Gen besteht (Abbildung 2B). Wenn der Käfig über seinen Oligonukleotid-Tether an das RNAP gebunden ist, stoppt er die Polymeraseaktivität, indem er andere DNA-Vorlagen für die RNAP-Bindung überkompetiert, wodurch der RNAP in einen “OFF” -Zustand versetzt wird (Abbildung 2C).
Um die Polymerase in einen “ON”-Zustand zu aktivieren, wurden T7-DNA-Templates mit einzelsträngigen “Operator”-Domänen vor dem T7-Promotor des Gens entworfen. Die Operatordomäne (d.h. Domäne a*b* Abbildung 2C)kann so konstruiert werden, dass sie den Käfig über TMDSD aus dem RNAP verdrängt und die RNAP proximal zum T7-Promotor des Gens positioniert, wodurch die Transkription eingeleitet wird. Alternativ wurden auch DNA-Vorlagen entworfen, bei denen die Operatorsequenz komplementär zu Hilfs-Nukleinsäuresträngen war, die als “künstliche Transkriptionsfaktoren” bezeichnet werden (d. h. TFA- und TFB-Stränge in Abbildung 3A). Wenn beide Stränge in die Reaktion eingeführt werden, werden sie sich am Bedienerstandort zusammensetzen und eine neue pseudo-zusammenhängende Domäne a * b *erzeugen. Diese Domäne kann dann den Käfig über TMDSD verschieben, um die Transkription zu initiieren (Abbildung 3B). Diese Stränge können entweder exogen zugeführt oder hergestellt werden.
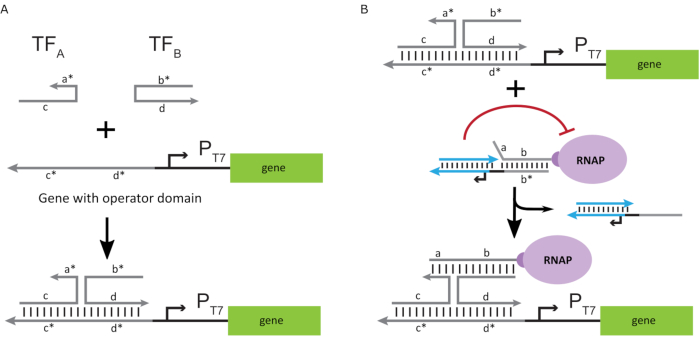
Abbildung 3: Selektive Programmierung der Polymeraseaktivität durch einen Drei-Komponenten-Schalteraktivator. (A) Wenn die Transkriptionsfaktoren (TFA und TFB) vorhanden sind, binden sie an die operatordomäne vor dem Promotor und bilden eine pseudo-einzelsträngige Sequenz (a*b*),die in der Lage ist, den Käfig durch Zehengriff-vermittelte DNA-Verschiebung zu verdrängen. (B) Diese a*b*-Domäne kann den Käfig über TMDSD verdrängen, um die Transkription zu initiieren. Diese Figur wurde von Chou und Shih27modifiziert. Abkürzungen: TF = Transkriptionsfaktor; RNAP = RNA-Polymerase; TMDSD = Toehold-vermittelte DNA-Strangverschiebung. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
Die Verwendung von Nukleinsäure-basierten Transkriptionsfaktoren für die In-vitro-Transkriptionsregulation ermöglicht die skalierbare Implementierung anspruchsvoller Schaltkreisverhaltensweisen wie digitale Logik, Feedback und Signalkaskadierung. Zum Beispiel kann man Logik-Gate-Kaskaden bauen, indem man Nukleinsäuresequenzen so entwirft, dass die Transkripte eines upstream-Gens ein downstreams Gen aktivieren. Eine Anwendung, die die Kaskadierung und das Multiplexing nutzt, die durch diese vorgeschlagene Technologie ermöglicht werden, ist die Entwicklung ausgefeilterer molekularer Computerschaltungen für die tragbare Diagnostik und molekulare Datenverarbeitung. Darüber hinaus kann die Integration der Molekularen Computer- und De-novo-RNA-Synthesefähigkeiten neue Anwendungen ermöglichen. Zum Beispiel kann ein molekularer Schaltkreis entworfen werden, um eine oder eine Kombination von benutzerdefinierten RNAs als therapeutische Input- und Output-RNAs oder mRNAs zu erkennen, die funktionelle Peptide oder Proteine für medizinische Point-of-Care-Anwendungen kodieren.
