La computación del ADN utiliza un conjunto de oligonucleótidos diseñados como medio para el cálculo. Estos oligonucleótidos están programados con secuencias para ensamblarse dinámicamente de acuerdo con la lógica especificada por el usuario y responder a entradas específicas de ácido nucleico. En los estudios de prueba de concepto, la salida del cálculo generalmente consiste en un conjunto de oligonucleótidos marcados fluorescentemente que se pueden detectar a través de electroforesis en gel o lectores de placas de fluorescencia. En los últimos 30 años, se han demostrado circuitos computacionales de ADN cada vez más complejos, como varias cascadas de lógica digital, redes de reacción química y redes neuronales1,2,3. Para ayudar con la preparación de estos circuitos de ADN, se han utilizado modelos matemáticos para predecir la funcionalidad de los circuitos genéticos sintéticos4,5,y se han desarrollado herramientas computacionales para el diseño de secuencias de ADN ortogonales6,7,8,9,10 . En comparación con las computadoras basadas en silicio, las ventajas de las computadoras de ADN incluyen su capacidad para interactuar directamente con biomoléculas, operar en solución en ausencia de una fuente de alimentación, así como su compacidad y estabilidad generales. Con el advenimiento de la secuenciación de próxima generación, el costo de sintetizar computadoras de ADN ha estado disminuyendo durante las últimas dos décadas a un ritmo más rápido que la Ley11de Moore. Las aplicaciones de tales computadoras basadas en ADN ahora están comenzando a surgir, como para el diagnóstico de enfermedades12,13, para alimentar la biofísica molecular14y como plataformas de almacenamiento de datos15.

Figura 1: Mecanismo de desplazamiento de la cadena de ADN mediada por el dedo del pie. El punto de apoyo, δ, es una secuencia libre y sin encuadernar en un dúplex parcial. Cuando se introduce un dominio complementario (δ*) en una segunda hebra, el dominio de δ libre sirve como punto de apoyo para la hibridación, permitiendo que el resto de la hebra (ɑ*) desplace lentamente a su competidor a través de una reacción reversible de compresión / descompresión conocida como migración de hebras. A medida que aumenta la duración de δ, el ΔG para la reacción hacia adelante disminuye y el desplazamiento ocurre más fácilmente. Haga clic aquí para ver una versión más grande de esta figura.
Hasta la fecha, la mayoría de las computadoras de ADN utilizan un motivo bien establecido en el campo de la nanotecnología dinámica del ADN conocido como desplazamiento de cadenas de ADN mediadas por dedo del pie (TMDSD, Figura 1)16. Este motivo consiste en un dúplex de ADN parcialmente de doble cadena (dsDNA) que muestra voladizos cortos de “puntera” (es decir, de 7 a 10 nucleótidos (nt)). Las hebras de “entrada” de ácido nucleico pueden interactuar con los dúplex parciales a través del punto de apoyo. Esto conduce al desplazamiento de una de las hebras del dúplex parcial, y esta hebra liberada puede servir como entrada para los dúplex parciales aguas abajo. Por lo tanto, TMDSD permite la señal en cascada y el procesamiento de información. En principio, los motivos ortogonales TMDSD pueden operar de forma independiente en solución, lo que permite el procesamiento paralelo de la información. Ha habido una serie de variaciones en la reacción de TMDSD, como el intercambio de hebras de ADN mediado por el punto de apoyo (TMDSE)17,los puntos de apoyo “sin fugas” con dominios de doble longitud18,los puntos de apoyo no coincidentes con la secuencia19y el desplazamiento de la hebra mediado por el “asidero”20. Estos principios de diseño innovadores permiten una energía y dinámica TMDSD más ajustadas para mejorar el rendimiento de la computación de ADN.
Los circuitos genéticos sintéticos, como los circuitos de genes transcripcionales, también son capaces de calcular21,22,23. Estos circuitos están regulados por factores de transcripción de proteínas, que activan o reprimen la transcripción de un gen uniéndose a elementos reguladores específicos del ADN. En comparación con los circuitos basados en ADN, los circuitos transcripcionales tienen varias ventajas. En primer lugar, la transcripción enzimática tiene una tasa de rotación mucho mayor que los circuitos de ADN catalítico existentes, generando así más copias de salida por copia única de entrada y proporcionando un medio más eficiente de amplificación de la señal. Además, los circuitos transcripcionales pueden producir diferentes moléculas funcionales, como aptámeros o ARN mensajero (ARNm) que codifican para proteínas terapéuticas, como resultados de cálculo, que pueden explotarse para diferentes aplicaciones. Sin embargo, una limitación importante de los circuitos transcripcionales actuales es su falta de escalabilidad. Esto se debe a que hay un conjunto muy limitado de factores de transcripción ortogonales basados en proteínas, y el diseño de novo de nuevos factores de transcripción de proteínas sigue siendo técnicamente desafiante y requiere mucho tiempo.
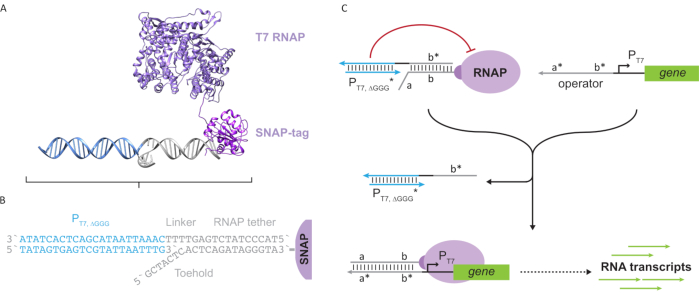
Figura 2: Abstracción y mecanismo del complejo polimerasa “tether” y “cage”. (A y B) Una correa de oligonucleótidos se marca enzimáticamente a una polimerasa T7 a través de la reacción SNAP-tag. Una jaula que consiste en un promotor T7 “falso” con un voladizo de complemento de amarre le permite hibridarse con la correa y bloquear la actividad transcripcional. (C) Cuando el operador (a*b*) está presente, se une al punto de apoyo de la correa del oligonucleótido (ab) y desplaza la región b* de la jaula, permitiendo que se produzca la transcripción. Esta figura ha sido modificada de Chou y Shih27. Abreviaturas: RNAP = ARN polimerasa. Haga clic aquí para ver una versión más grande de esta figura.
Este artículo presenta un nuevo bloque de construcción para la computación molecular que combina las funcionalidades de los circuitos transcripcionales con la escalabilidad de los circuitos basados en ADN. Este bloque de construcción es un RNAP T7 unido covalentemente con una correa de ADN de cadena simple(Figura 2A). Para sintetizar este ARNP T7 atado al ADN, la polimerasa se fusionó con un SNAP-tag24 N-terminal y se expresó recombinantemente en Escherichia coli. La etiqueta SNAP se reaccionó con un oligonucleótido funcionalizado con el sustrato BG. La correa de oligonucleótidos permite el posicionamiento de los huéspedes moleculares en estrecha proximidad a la polimerasa a través de la hibridación del ADN. Uno de esos invitados fue un bloqueador transcripcional competitivo conocido como “jaula”, que consiste en un dúplex de ADN promotor T7 “falso” sin gen aguasabajo (Figura 2B). Cuando se une al RNAP a través de su correa de oligonucleótidos, la jaula detiene la actividad de la polimerasa al superar a otras plantillas de ADN para la unión al RNAP, lo que hace que el RNAP esté en un estado “OFF”(Figura 2C).
Para activar la polimerasa a un estado “ON”, se diseñaron plantillas de ADN T7 con dominios “operador” monocatenarios aguas arriba del promotor T7 del gen. El dominio operador (es decir, dominio a*b* Figura 2C)puede diseñarse para desplazar la jaula del RNAP a través de TMDSD y posicionar el RNAP proximal al promotor T7 del gen, iniciando así la transcripción. Alternativamente, también se diseñaron plantillas de ADN donde la secuencia del operador era complementaria a las hebras auxiliares de ácido nucleico que se conocen como “factores de transcripción artificiales” (es decir, hebras TFA y TFB en la Figura 3A). Cuando ambas hebras se introducen en la reacción, se ensamblarán en el sitio del operador, creando un nuevo dominio pseudo-contiguo a*b*. Este dominio puede desplazar la jaula a través de TMDSD para iniciar la transcripción(Figura 3B). Estas hebras pueden ser suministradas exógenamente o producidas.
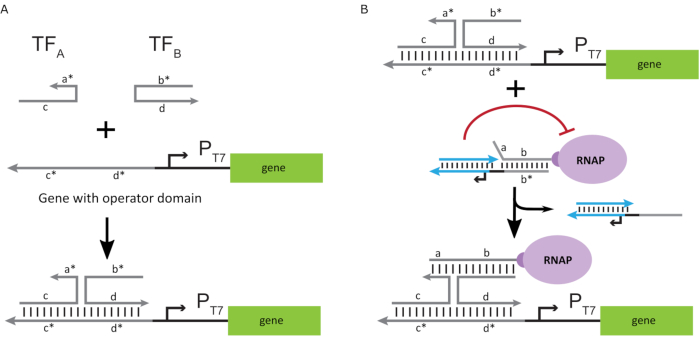
Figura 3: Programación selectiva de la actividad de la polimerasa a través de un activador de interruptor de tres componentes. (A) Cuando los factores de transcripción (TFA y TFB)están presentes, se unen al dominio del operador aguas arriba del promotor, formando una secuencia pseudo de cadena simple (a*b*) capaz de desplazar la jaula a través del desplazamiento del ADN mediado por el punto de apoyo. (B) Este dominio a*b* puede desplazar la jaula a través de TMDSD para iniciar la transcripción. Esta figura ha sido modificada de Chou y Shih27. Abreviaturas: TF = factor de transcripción; RNAP = ARN polimerasa; TMDSD = desplazamiento de la cadena de ADN mediada por el dedo del pie. Haga clic aquí para ver una versión más grande de esta figura.
El uso de factores de transcripción basados en ácidos nucleicos para la regulación transcripcional in vitro permite la implementación escalable de comportamientos de circuitos sofisticados como la lógica digital, la retroalimentación y la señal en cascada. Por ejemplo, se pueden construir cascadas de puertas lógicas diseñando secuencias de ácidos nucleicos de tal manera que las transcripciones de un gen aguas arriba activen un gen aguas abajo. Una aplicación que explota la cascada y la multiplexación que esta tecnología propuesta hace capaces es el desarrollo de circuitos de computación molecular más sofisticados para diagnósticos portátiles y procesamiento de datos moleculares. Además, la integración de la computación molecular y las capacidades de síntesis de ARN de novo puede permitir nuevas aplicaciones. Por ejemplo, se puede diseñar un circuito molecular para detectar uno o una combinación de ARN definidos por el usuario como ARN terapéuticos de entrada y salida o ARNm que codifican péptidos o proteínas funcionales para aplicaciones médicas en el punto de atención.
