A computação em DNA usa um conjunto de oligonucleotídeos projetados como meio de computação. Esses oligonucleotídeos são programados com sequências para serem montados dinamicamente de acordo com a lógica especificada pelo usuário e responder a entradas específicas de ácido nucleico. Em estudos de prova de conceito, a saída da computação normalmente consiste em um conjunto de oligonucleotídeos fluorescentes rotulados que podem ser detectados através de leitores de eletroforese de gel ou fluorescência. Ao longo dos últimos 30 anos, foram demonstrados circuitos computacionais de DNA cada vez mais complexos, como várias cascatas lógicas digitais, redes de reação química e redes neurais1,2,3. Para auxiliar na preparação desses circuitos de DNA, modelos matemáticos têm sido usados para prever a funcionalidade dos circuitos genéticos sintéticos4,5, e ferramentas computacionais foram desenvolvidas para o projeto de sequência de DNA ortogonal6,7,8,9,10 . Em comparação com computadores baseados em silício, as vantagens dos computadores de DNA incluem sua capacidade de interagir diretamente com biomoléculas, operar em solução na ausência de uma fonte de alimentação, bem como sua compactação e estabilidade globais. Com o advento do sequenciamento da próxima geração, o custo de sintetizar computadores de DNA vem diminuindo nas últimas duas décadas a uma taxa mais rápida do que a Lei11de Moore. As aplicações desses computadores baseados em DNA estão começando a surgir, como para o diagnóstico de doenças12,13, para alimentar a biofísica molecular14, e como plataformas de armazenamento de dados15.

Figura 1: Mecanismo de deslocamento da cadeia de DNA mediado por toehold. O toehold, δ, é uma sequência livre e desvinculada em um duplex parcial. Quando um domínio complementar (δ*) é introduzido em uma segunda vertente, o domínio δ livre serve como um toehold para hibridização, permitindo que o resto da cadeia (ônica*) desloque lentamente seu concorrente através de uma reação reversível zipping/unzipping conhecida como migração de fios. À medida que o comprimento do δ aumenta, o ΔG para a reação para a frente diminui, e o deslocamento acontece mais facilmente. Clique aqui para ver uma versão maior desta figura.
Até o momento, a maioria dos computadores de DNA utilizam um motivo bem estabelecido no campo da nanotecnologia dinâmica de DNA conhecida como deslocamento de fios de DNA mediados por toehold (TMDSD, Figura 1)16. Este motivo consiste em um duplex de DNA parcialmente duplo (dsDNA) exibindo saliências curtas de “toehold” (ou seja, 7 a 10 nucleotídeos (nt)). Os fios de “entrada” de ácido nucleico podem interagir com os duplexes parciais através do dedo do dedo do sol. Isso leva ao deslocamento de um dos fios do duplex parcial, e este fio liberado pode então servir como entrada para duplexes parciais a jusante. Assim, o TMDSD permite a cascata de sinais e o processamento de informações. Em princípio, os motivos ortogonais de TMDSD podem operar de forma independente na solução, permitindo o processamento paralelo de informações. Houve uma série de variações na reação TMDSD, como a troca de fios de DNA mediada por toehold (TMDSE)17, toeholds “sem vazamento” com domínios de dois comprimentos18, dedos incompatíveis de sequência19e deslocamento de fios mediados por “handhold”20. Esses princípios inovadores de design permitem energias tmdsd mais finamente ajustadas e dinâmicas para melhorar o desempenho da computação de DNA.
Circuitos genéticos sintéticos, como circuitos genéticos transcricionais, também são capazes de calcular21,22,23. Esses circuitos são regulados por fatores de transcrição proteica, que ativam ou reprimem transcrição de um gene ligando-se a elementos específicos de DNA regulatório. Comparados com circuitos baseados em DNA, circuitos transcricionais têm várias vantagens. Em primeiro lugar, a transcrição enzimática tem uma taxa de rotatividade muito maior do que os circuitos de DNA catalíticos existentes, gerando assim mais cópias de saída por cópia única de entrada e fornecendo um meio mais eficiente de amplificação de sinal. Além disso, circuitos transcricionais podem produzir diferentes moléculas funcionais, como aptamers ou codificação de RNA (mRNA) mensageiro para proteínas terapêuticas, como saídas de computação, que podem ser exploradas para diferentes aplicações. No entanto, uma grande limitação dos circuitos transcricionais atuais é a falta de escalabilidade. Isso ocorre porque há um conjunto muito limitado de fatores de transcrição ortogonais baseados em proteínas, e o novo desenho de novos fatores de transcrição proteica permanece tecnicamente desafiador e demorado.
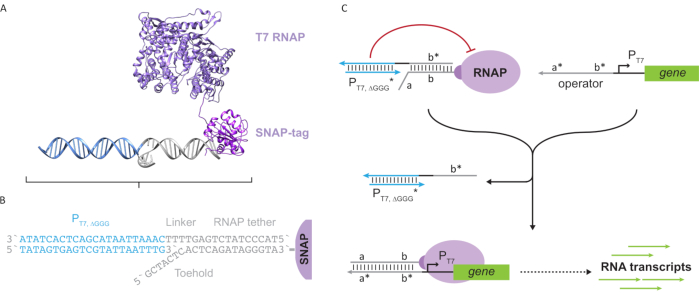
Figura 2: Abstração e mecanismo do complexo de polimerase “tether” e “cage” ( A e B) Uma corda oligonucleotídeo é enzimáticamente rotulada para uma polimerase T7 através da reação snap-tag. Uma gaiola composta por um promotor T7 “falso” com uma saliência complementar de tether permite hibridizar a atividade transcricional de corda e bloco. (C) Quando o operador(a*b*) está presente, ele se liga ao toehold sobre a corda oligonucleotídeo(ab)e desloca a região b* da gaiola, permitindo que a transcrição ocorra. Este número foi modificado de Chou e Shih27. Abreviaturas: RNAP = RNA polymerase. Clique aqui para ver uma versão maior desta figura.
Este artigo introduz um novo bloco de construção para computação molecular que combina as funcionalidades dos circuitos transcricionais com a escalabilidade dos circuitos baseados em DNA. Este bloco de construção é um T7 RNAP covalentemente anexado com uma corda de DNA de um único fio(Figura 2A). Para sintetizar este T7 RNAP ligado ao DNA, a polimerase foi fundida a um SNAP-tag24 n-terminal e recombinantemente expressa em Escherichia coli. A tag SNAP foi então reagida com um oligonucleotídeo funcionalizado com o substrato BG. A corda oligonucleotídeo permite o posicionamento de hóspedes moleculares nas proximidades da polimerase através da hibridização do DNA. Um desses convidados foi um bloqueador transcricional competitivo referido como uma “gaiola”, que consiste em um duplex de DNA “falso” do promotor T7 sem gene a jusante(Figura 2B). Quando vinculada ao RNAP através de sua corda oligonucleotídeo, a gaiola paralisa a atividade de polimerase, superando outros modelos de DNA para a vinculação RNAP, tornando o RNAP em um estado “OFF”(Figura 2C).
Para ativar a polimerase a um estado “ON”, foram projetados modelos de DNA T7 com domínios “operadores” de uma única linha a montante do promotor T7 do gene. O domínio do operador (ou seja, domínio a*b* Figura 2C) pode ser projetado para deslocar a gaiola do RNAP via TMDSD e posicionar o proximal RNAP ao promotor T7 do gene, iniciando assim a transcrição. Alternativamente, foram projetados modelos de DNA onde a sequência do operador era complementar aos fios auxiliares de ácido nucleico que são chamados de “fatores de transcrição artificial” (ou seja, fios TFA e TFB na Figura 3A). Quando ambas as vertentes forem introduzidas na reação, elas se reunirão no site do operador, criando um novo domínio pseudo-contíguo a*b*. Este domínio pode então deslocar a gaiola via TMDSD para iniciar a transcrição(Figura 3B). Estes fios podem ser fornecidos exogenously ou produzidos.
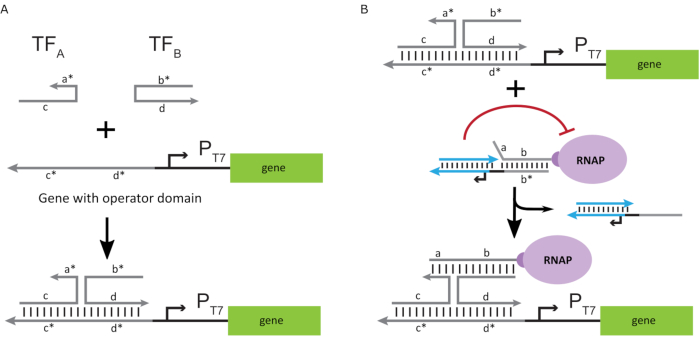
Figura 3: Programação seletiva da atividade de polimerase através de um ativador de interruptor de três componentes. (A) Quando os fatores de transcrição (TFA e TFB) estão presentes, eles se ligam ao domínio do operador a montante do promotor, formando uma sequência pseudo de uma única-strand(a*b*) capaz de deslocar a gaiola através do deslocamento mediado do DNA. (B) Este domínio a*b* pode deslocar a gaiola via TMDSD para iniciar a transcrição. Este número foi modificado de Chou e Shih27. Abreviaturas: TF = fator de transcrição; RNAP = polimerase de RNA; TMDSD = deslocamento de fios de DNA mediados por toehold. Clique aqui para ver uma versão maior desta figura.
O uso de fatores de transcrição nucleicos baseados em ácido para regulação transcricional in vitro permite a implementação escalável de comportamentos sofisticados de circuito, como lógica digital, feedback e cascata de sinais. Por exemplo, pode-se construir cascatas lógicas do portão projetando sequências de ácido nucleico de tal forma que as transcrições de um gene a montante ativam um gene a jusante. Uma aplicação que explora a cascata e multiplexing capazes por essa tecnologia proposta é o desenvolvimento de circuitos de computação molecular mais sofisticados para diagnósticos portáteis e processamento de dados moleculares. Além disso, integrar os recursos de computação molecular e síntese de novo RNA pode permitir novas aplicações. Por exemplo, um circuito molecular pode ser projetado para detectar uma ou uma combinação de RNAs definidas pelo usuário como insumos e saída de RNAs terapêuticos ou mRNAs codificando peptídeos funcionais ou proteínas para aplicações médicas de ponto de cuidado.
