Onderzoeken van secundair metabolisme bestaan vaak uit het screenen van ruwe extracten voor specifieke biologische activiteiten, gevolgd door zuivering, identificatie en karakterisering van de bestanddelen die behoren tot actieve fracties. Dit proces is efficiënt gebleken en heeft de isolatie van verschillende chemische entiteiten bevorderd. Tegenwoordig wordt dit echter als onhaalbaar gezien, vooral vanwege de hoge herontdekkingspercentages. Aangezien de farmaceutische industrie zonder kennis van de rollen en de functies van gespecialiseerde metabolieten een revolutie teweegbracht, werd hun identificatie uitgevoerd onder laboratoriumomstandigheden die niet nauwkeurig aardvertegenwoordigen 1. Vandaag de dag is er een beter begrip van natuurlijke signalering seinen invloeden, afscheiding, en de aanwezigheid van de meeste doelen bij niet op te sporen lage concentraties. Bovendien zal de regulering van het proces de academische gemeenschap en de farmaceutische industrie helpen om van deze kennis gebruik te maken. Het zal ook ten goede komen aan onderzoek naar directe isolatie van metabolieten in verband met stille biosynthetische genclusters (BGC’s)2.
In deze context hebben de vooruitgang in genomische sequencing hernieuwde interesse in het screenen van micro-organismen metabolieten. Dit komt omdat het analyseren van de genomische informatie van onbedekte biosynthetische clusters kan onthullen genen coderen nieuwe verbindingen niet waargenomen of geproduceerd onder laboratoriumomstandigheden. Veel microbiële hele genoom projecten of ontwerpen zijn beschikbaar vandaag, en het aantal groeit elk jaar, het verstrekken van enorme vooruitzichten voor het blootleggen van nieuwe bioactieve moleculen door middel van genoom mijnbouw3,4.
De Atlas van Biosynthetische Gen Clusters is de huidige grootste verzameling van automatisch gedolzegenclusters als onderdeel van het Integrated Microbial Genomes Platform van het Joint Genome Institute (JGI IMG-ABC)2. Meest recent heeft het Minimum Information for Biosynthetic Gene Clusters (MIBiG) Standardization Initiative de handmatige reannotatie van BGC’s bevorderd, met een sterk samengestelde referentiedataset5. Tegenwoordig zijn er tal van instrumenten beschikbaar om computationele mijnbouw van genetische gegevens en hun verbinding met bekende secundaire metabolieten mogelijk te maken. Er zijn ook verschillende strategieën ontwikkeld om toegang te krijgen tot nieuwe bioactieve natuurlijke producten (d.w.z. heterologe expressie, doelgenverwijdering, in vitro reconstructie, genomische sequentie, isotopengeleide screening [genomisotopische benadering], manipulatie van lokale en mondiale regelgevers, op resistentie gebaseerde mijnbouw, cultuuronafhankelijke mijnbouw en, meer recentelijk, MS-geleide/codebenaderingen2,6,7,8,9, 10,11,12,13,14,15).
Genoommining als enkelvoudstrategie vereist inspanningen om een enkele of kleine groep moleculen te annoteren; er blijven dus hiaten in het proces bestaan waarin nieuwe verbindingen prioriteit krijgen voor isolatie en structuuropheldering. In principe zijn deze benaderingen slechts gericht op één biosynthetisch traject per experiment, wat resulteert in een langzame ontdekkingssnelheid. In die zin is het gebruik van GM samen met een moleculaire netwerkbenadering een belangrijke vooruitgang voor het onderzoek naar natuurlijke producten14,15.
De veelzijdigheid, nauwkeurigheid en hoge gevoeligheid van vloeibare chromatografie-massaspectrometrie (LC-MS) maken het een goede methode voor samengestelde identificatie. Momenteel hebben verschillende platforms geïnvesteerd algoritmen en software suites voor ongerichte metabolomics16,17,18,19,20. De kern van deze programma’s omvat functiedetectie (peak picking)21 en piekuitlijning, waardoor identieke functies in een batch van monsters kunnen worden gematcht en naar patronen wordt gezocht. MS-patroongebaseerde algoritmen22,23 vergelijken karakteristieke fragmentatiepatronen en matchen MS2-overeenkomsten die moleculaire families genereren die structurele kenmerken delen. Deze kenmerken kunnen vervolgens worden gemarkeerd en geclusterd, waardoor de mogelijkheid om snel te ontdekken bekende en onbekende moleculen uit een complex biologisch extract door tandem MS2,24,25. Daarom is tandem MS een veelzijdige methode om structurele informatie te verkrijgen over verschillende chemotypes in een grote hoeveelheid gegevens tegelijk.
Het Global Natural Products Social Molecular Networking (GNPS)26 algoritme gebruikt de genormaliseerde fragmentionenintensiteit om multidimensionale vectoren te construeren, waarbij gelijkenissen worden vergeleken met behulp van een cosinefunctie. De relatie tussen verschillende bovenliggende ionen wordt uitgezet in een diagramweergave, waarbij elke fragmentatie wordt gevisualiseerd als een knooppunt (cirkels) en de verwantheid van elk knooppunt wordt gedefinieerd door een rand (lijnen). De globale visualisatie van moleculen uit één bron wordt gedefinieerd als een moleculair netwerk. Structureel uiteenlopende moleculen die uniek fragmenteren, vormen hun eigen specifieke cluster of constellatie, terwijl verwante moleculen samenclusteren. Clustering chemotypes maakt het mogelijk de hypothetische verbinding van soortgelijke structurele kenmerken aan hun biosynthetische oorsprong.
Het combineren van zowel chemotype-to-genotype en genotype-to-chemotype benaderingen is krachtig bij het creëren van bio-informatica verbindingen tussen BGCs en hun kleine molecuul producten27. Daarom is MS-geleide genoommijnbouw een snelle methode en een lage materiaalverbruikende strategie, en het helpt bij het overbruggen van ouderionen en biosynthetische trajecten die door WGS van een of meer stammen onder diverse metabolische en milieuomstandigheden worden onthuld.
De workflow van dit protocol (figuur 1) bestaat uit het voeden van WGS-gegevens in een biosynthetisch genclusterannotatieplatform zoals antiSMASH28,29,30. Het helpt bij het schatten van de verscheidenheid van verbindingen en de klasse van verbindingen gecodeerd door het genoom. Er moet een strategie worden aangenomen om zich te richten op een biosynthetisch gencluster dat een chemische entiteit van belang codeert, en kweekextracten van een wilde soortstam en/of heterologe stam die de BGC bevat, kunnen worden geanalyseerd om geclusterde ionen te genereren op basis van gelijkenissen met GNPS26,31. Bijgevolg is het mogelijk om nieuwe moleculen te identificeren die zich associëren met de beoogde BGC en niet beschikbaar zijn in de database (voornamelijk onbekende analogen, soms geproduceerd in lage titers). Het is relevant om te bedenken dat gebruikers kunnen bijdragen aan deze platforms en dat de beschikbaarheid van bioinformatica en MS/MS-gegevens snel toeneemt, wat leidt tot een constante ontwikkeling en upgrade van effectieve computationele tools en algoritmen om efficiënte verbindingen van complexe extracten met moleculen te begeleiden.
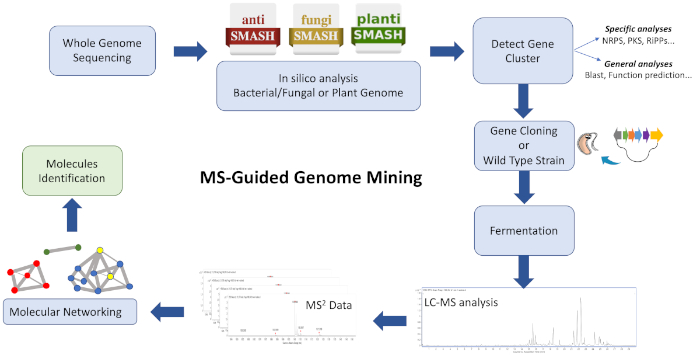
Figuur 1: Overzicht van de gehele werkstroom. Getoond is een illustratie van de bio-informatica, klonen, en moleculaire netwerkstappen die betrokken zijn bij de beschreven MS-geleide genoom mijnbouw aanpak om nieuwe metabolieten te identificeren. Klik hier om een grotere versie van dit cijfer te bekijken.
Dit protocol beschrijft een snelle en efficiënte workflow om genoommining en moleculaire netwerken te combineren als uitgangspunt voor de pijplijn voor de ontdekking van natuurlijke producten. Hoewel veel toepassingen in staat zijn om de samenstelling en verwantschap van MS-detecteerbare moleculen in één netwerk te visualiseren, worden er hier verschillende aangenomen om structureel vergelijkbare geclusterde moleculen te visualiseren. Met behulp van deze strategie, nieuwe cyclodepsipeptide producten waargenomen in metabole extracten van Streptomyces sp. CBMAI 2042 zijn met succes geïdentificeerd. Geleid door genoommijnbouw wordt de hele biosynthetische genclustercodering voor valinomycines erkend en gekloond in de producentenstam Streptomyces coelicolor M1146. Ten slotte, na een MS-patroon gebaseerde moleculaire netwerken, de moleculen gedetecteerd door MS zijn gecorreleerd met BGCs die verantwoordelijk zijn voor hun biogenese32.
