Untersuchungen des Sekundärstoffwechsels bestehen häufig darin, Rohextrakte auf spezifische biologische Aktivitäten zu untersuchen, gefolgt von Reinigung, Identifizierung und Charakterisierung der Bestandteile aktiver Fraktionen. Dieser Prozess hat sich als effizient erwiesen und die Isolierung mehrerer chemischer Einheiten gefördert. Heutzutage wird dies jedoch als undurchführbar angesehen, vor allem aufgrund der hohen Wiederentdeckungsraten. Als die pharmazeutische Industrie revolutionierte, ohne die Rollen und Funktionen spezialisierter Metaboliten zu kennen, wurde ihre Identifizierung unter Laborbedingungen durchgeführt, die die Natur nicht genau darstellten1. Heute gibt es ein besseres Verständnis von natürlichen Signaleinflüssen, Sekretion und das Vorhandensein der meisten Ziele bei nicht nachweisbar niedrigen Konzentrationen. Darüber hinaus wird die Regulierung des Prozesses der akademischen Gemeinschaft und der pharmazeutischen Industrie helfen, dieses Wissen zu nutzen. Es wird auch der Forschung zugute kommen, die die direkte Isolierung von Metaboliten im Zusammenhang mit stillen biosynthetischen Genclustern (BGCs)2betrifft.
In diesem Zusammenhang haben Fortschritte bei der genomischen Sequenzierung das Interesse an screening-Mikroorganismenmetaboliten erneut geweckt. Dies liegt daran, dass die Analyse der genomischen Informationen von nicht entdeckten biosynthetischen Clustern Gene aufdecken kann, die neuartige Verbindungen kodieren, die nicht beobachtet oder unter Laborbedingungen produziert werden. Viele mikrobielle ganze Genomprojekte oder Entwürfe sind heute verfügbar, und die Zahl wächst jedes Jahr, was massive Aussichten für die Entdeckung neuer bioaktiver Moleküle durch Genomabbau3,4bietet.
Der Atlas der biosynthetischen Gencluster ist die derzeit größte Sammlung automatisch abgebauter Gencluster als Bestandteil der Integrated Microbial Genomes Platform des Joint Genome Institute (JGI IMG-ABC)2. Zuletzt hat die Standardisierungsinitiative Minimum Information for Biosynthetic Gene Clusters (MIBiG) die manuelle Reannotation von BGCs gefördert und einen hochgradig kuratierten Referenzdatensatz 5 zur Verfügunggestellt. Heutzutage stehen viele Werkzeuge zur Verfügung, um das rechnerische Mining genetischer Daten und deren Verbindung zu bekannten sekundären Metaboliten zu ermöglichen. Außerdem wurden verschiedene Strategien für den Zugang zu neuen bioaktiven Naturprodukten entwickelt (z. B. heterologe Expression, Zielgenlöschung, In-vitro-Rekonstitution, genomische Sequenz, isotopengeführtes Screening [genomisotopen Ansatz], Manipulation lokaler und globaler Regulierungsbehörden, resistenzzielbasierter Bergbau, kulturunabhängiger Bergbau und in jüngerer Zeit MS-geführte/code-Ansätze2,6,7,8,9, 10,11,12,13,14,15).
Genomabbau als einzigartige Strategie erfordert Anstrengungen, um eine einzelne oder kleine Gruppe von Molekülen zu kommentieren; So bleiben Lücken im Prozess, in denen neue Verbindungen für Isolation und Strukturaufklärung priorisiert werden. Im Prinzip zielen diese Ansätze nur auf einen biosynthetischen Pfad pro Experiment ab, was zu einer langsamen Entdeckungsrate führt. In diesem Sinne stellt die Verwendung von GM zusammen mit einem molekularen Vernetzungsansatz einen wichtigen Fortschritt für die Naturproduktforschungdar 14,15.
Die Vielseitigkeit, Genauigkeit und hohe Empfindlichkeit der Flüssigchromatographie-Massenspektrometrie (LC-MS) machen es zu einer guten Methode zur zusammengesetzten Identifizierung. Derzeit haben mehrere Plattformen Algorithmen und Software-Suiten für ungezielte Metabolomik16,17,18,19,20investiert. Der Kern dieser Programme umfasst die Feature-Erkennung (Peak Picking)21 und die Spitzenausrichtung, die die Übereinstimmung identischer Features über einen Stapel von Samples und die Suche nach Mustern ermöglicht. MS-Muster-basierte Algorithmen22,23 vergleichen charakteristische Fragmentierungsmuster und stimmen MS2-Ähnlichkeiten überein, die molekulare Familien mit strukturellen Merkmalen erzeugen. Diese Merkmale können dann hervorgehoben und gebündelt werden, was die Fähigkeit verleiht, bekannte und unbekannte Moleküle aus einem komplexen biologischen Extrakt durch Tandem MS2,24,25schnell zu entdecken. Daher ist Tandem MS eine vielseitige Methode, um strukturelle Informationen über mehrere Chemotypen zu erhalten, die in einer großen Datenmenge gleichzeitig enthalten sind.
Der Global Natural Products Social Molecular Networking (GNPS)26-Algorithmus verwendet die normalisierte Fragmentionen-Intensität, um multidimensionale Vektoren zu konstruieren, bei denen Ähnlichkeiten mit einer Kosinusfunktion verglichen werden. Die Beziehung zwischen verschiedenen übergeordneten Ionen wird in einer Diagrammdarstellung dargestellt, in der jede Fragmentierung als Knoten (Kreise) visualisiert wird und die Verwandtschaft jedes Knotens durch eine Kante (Linien) definiert wird. Die globale Visualisierung von Molekülen aus einer Hand wird als molekulares Netzwerk definiert. Strukturell divergierende Moleküle, die auf einzigartige Weise fragmentieren, bilden ihren eigenen spezifischen Cluster oder ihre eigene Konstellation, während sich verwandte Moleküle zusammenschließen. Clustering-Chemotypen ermöglichen die hypothetische Verbindung ähnlicher struktureller Merkmale mit ihren biosynthetischen Ursprüngen.
Die Kombination sowohl von Chemotyp-zu-Genotyp- als auch von Genotyp-zu-Chemotyp-Ansätzen ist eine starke Wirkung, wenn es darum geht, Bioinformatik-Verbindungen zwischen BGCs und ihren kleinen Molekülprodukten herzustellen27. Daher ist MS-geführter Genomabbau eine schnelle Methode und eine strategie mit geringem Materialverbrauch, und es hilft, Elternionen und biosynthetische Wege zu überbrücken, die von WGS einer oder mehrerer Stämme unter verschiedenen metabolischen und ökologischen Bedingungen aufgedeckt wurden.
Der Workflow dieses Protokolls (Abbildung 1) besteht darin, WGS-Daten in eine biosynthetische Gencluster-Anmerkungsplattform wie antiSMASH28,29,30einzuspeisen. Es hilft, die Vielfalt der Verbindungen und Klasse der Verbindungen durch das Genom kodiert zu schätzen. Es muss eine Strategie zur Zielart ierung eines biosynthetischen Genclusters angenommen werden, der für eine chemische Einheit von Interesse kodiert, und Kulturextrakte aus einem WildenStamm und/oder heterologen Stamm, der den BGC enthält, können analysiert werden, um clusterierte Ionen auf der Grundlage von Ähnlichkeiten mit GNPS26,31zu erzeugen. Folglich ist es möglich, neue Moleküle zu identifizieren, die mit dem zielgerichteten BGC assoziiert werden und in der Datenbank nicht verfügbar sind (hauptsächlich unbekannte Analoga, manchmal in niedrigen Tistern produziert). Es ist wichtig zu berücksichtigen, dass Benutzer zu diesen Plattformen beitragen können und dass die Verfügbarkeit von Bioinformatik und MS/MS-Daten rapide zunimmt, was zu einer ständigen Weiterentwicklung und Aktualisierung effektiver Rechenwerkzeuge und Algorithmen führt, um effiziente Verbindungen komplexer Extrakte mit Molekülen zu steuern.
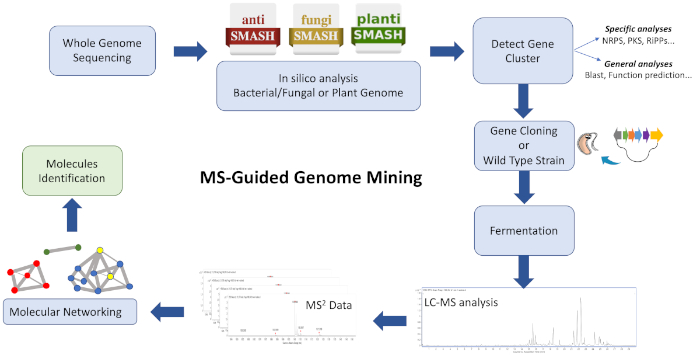
Abbildung 1: Übersicht über den gesamten Workflow. Gezeigt wird eine Illustration der bioinformatischen, klonenden und molekularen Vernetzungsschritte, die im beschriebenen MS-geführten Genom-Mining-Ansatz zur Identifizierung neuer Metaboliten beteiligt sind. Bitte klicken Sie hier, um eine größere Version dieser Abbildung anzuzeigen.
Dieses Protokoll beschreibt einen schnellen und effizienten Workflow, um Genom-Mining und molekulare Vernetzung als Ausgangspunkt für die Pipeline zur Entdeckung natürlicher Produkte zu kombinieren. Obwohl viele Anwendungen in der Lage sind, die Zusammensetzung und Verwandtheit von MS-detektierbaren Molekülen in einem Netzwerk zu visualisieren, werden hier mehrere verwendet, um strukturell ähnliche gruppierte Moleküle zu visualisieren. Mit dieser Strategie, neuartige Cyclodepsipeptid Produkte in metabolischen Extrakten von Streptomyces sp. CBMAI 2042 beobachtet werden erfolgreich identifiziert. Geleitet vom Genombergbau wird der gesamte biosynthetische Gencluster, der für Valinomycine kodiert, erkannt und in den Produzentenstamm Streptomyces coelicolor M1146 geklont. Schließlich korrelieren die von MS nachgewiesenen Moleküle nach einer MS-Muster-basierten molekularen Vernetzung mit BGCs, die für ihre Biogenese verantwortlich sind32.
