Les études sur le métabolisme secondaire consistent souvent à filtrer des extraits bruts pour des activités biologiques spécifiques suivies de la purification, de l’identification et de la caractérisation des constituants appartenant à des fractions actives. Ce processus s’est avéré efficace, favorisant l’isolement de plusieurs entités chimiques. Cependant, aujourd’hui, cela est considéré comme irréalisable, principalement en raison des taux élevés de redécouverte. Comme l’industrie pharmaceutique a révolutionné sans connaître les rôles et les fonctions des métabolites spécialisés, leur identification a été effectuée dans des conditions de laboratoire qui ne représentaient pas exactement la nature1. Aujourd’hui, il y a une meilleure compréhension des influences naturelles de signalisation, de la sécrétion, et de la présence de la plupart des cibles à des concentrations anormalement basses. De plus, la réglementation du processus aidera la communauté universitaire et l’industrie pharmaceutique à tirer parti de ces connaissances. Il bénéficiera également à la recherche impliquant l’isolement direct des métabolites liés aux grappes de gènes biosynthétiques silencieuses (BGC)2.
Dans ce contexte, les progrès du séquençage génomique ont renouvelé leur intérêt pour le dépistage des métabolites micro-organismes. C’est parce que l’analyse de l’information génomique des amas biosynthétiques non découverts peut révéler des gènes codant de nouveaux composés non observés ou produits dans des conditions de laboratoire. De nombreux projets ou projets de génome entier microbien sont disponibles aujourd’hui, et le nombre augmente chaque année, offrant des perspectives massives pour découvrir de nouvelles molécules bioactives grâce à l’exploitation minière du génome3,4.
L’Atlas of Biosynthetic Gene Clusters est la plus grande collection actuelle de grappes de gènes automatiquement extraites en tant que composant de la plate-forme intégrée des génomes microbiens de l’Institut mixte du génome (JGI IMG-ABC)2. Plus récemment, l’Initiative de normalisation des grappes de gènes biosynthétiques (MIBiG) a favorisé la reannotation manuelle des BGC, fournissant un ensemble de données de référence très organisé5. Aujourd’hui, de nombreux outils sont disponibles pour permettre l’extraction informatique des données génétiques et leur connexion aux métabolites secondaires connus. Différentes stratégies ont également été élaborées pour accéder à de nouveaux produits naturels bioactifs (c.-à-d. l’expression hétérogène, la suppression des gènes cibles, la reconstitution in vitro, la séquence génomique, le dépistage guidé par isotopes [approche génoto-américaine], la manipulation des régulateurs locaux et mondiaux, l’exploitation minière axée sur les cibles de résistance, l’exploitation minière indépendante de la culture et, plus récemment, les approches de ms-guided/code2,6,7,8,9, 10,11,12,13,14,15).
L’extraction du génome comme stratégie singulière nécessite des efforts pour annoter un seul ou un petit groupe de molécules; ainsi, des lacunes subsistent dans le processus dans lequel de nouveaux composés sont priorisés pour l’isolement et l’élucidation de la structure. En principe, ces approches ne ciblent qu’une seule voie biosynthétique par expérience, ce qui entraîne un faible taux de découverte. En ce sens, l’utilisation de GM avec une approche de réseautage moléculaire représente une avancée importante pour la recherche sur les produits naturels14,15.
La polyvalence, la précision et la sensibilité élevée de la spectrométrie de masse chromatographie liquide (LC-MS) en font une bonne méthode d’identification composée. Actuellement, plusieurs plates-formes ont investi des algorithmes et des suites logicielles pour métabolomiques non ciblés16,17,18,19,20. Le cœur de ces programmes comprend la détection des fonctionnalités (pic de sélection)21 et l’alignement de pointe, ce qui permet de faire correspondre des caractéristiques identiques à travers un lot d’échantillons et de rechercher des modèles. Les algorithmes basés sur les modèles de SP22,23 comparent les modèles caractéristiques de fragmentation et correspondent aux similitudes de MS2 générant des familles moléculaires partageant des caractéristiques structurelles. Ces caractéristiques peuvent ensuite être mises en évidence et regroupées, conférant la possibilité de découvrir rapidement des molécules connues et inconnues à partir d’un extrait biologique complexe par tandem MS2,24,25. Par conséquent, la SP tandem est une méthode polyvalente pour obtenir des informations structurelles de plusieurs chemotypes contenus dans une grande quantité de données simultanément.
L’algorithme Global Natural Products Social Molecular Networking (GNPS)26 utilise l’intensité normalisée des ions fragmentés pour construire des vecteurs multidimensionnels, dans lesquels les similitudes sont comparées à l’aide d’une fonction cosine. La relation entre les différents ions parentaux est tracée dans une représentation de diagramme, dans laquelle chaque fragmentation est visualisée comme un nœud (cercles), et la relation de chaque nœud est définie par un bord (lignes). La visualisation globale des molécules à partir d’une seule source est définie comme un réseau moléculaire. Des molécules structurellement divergentes qui se fragmentent de façon unique formeront leur propre amas ou constellation spécifique, tandis que les molécules apparentées s’assemblent. Les chemotypes de regroupement permettent la connexion hypothétique de caractéristiques structurelles similaires à leurs origines biosynthétiques.
La combinaison des approches chemotype-génotype et génotype-chemotype est puissante lors de la création de liens bioinformatiques entre les BGC et leurs produits à petites molécules27. Par conséquent, l’extraction du génome guidée par ms est une méthode rapide et une stratégie peu consommatrice de matériaux, et elle aide à combler les ions parentaux et les voies biosynthétiques révélées par WGS d’une ou plusieurs souches dans diverses conditions métaboliques et environnementales.
Le flux de travail de ce protocole (figure 1) consiste à alimenter les données WGS dans une plate-forme d’annotation de grappes génétiques biosynthétiques telles que l’antiSMASH28,29,30. Il permet d’estimer la variété des composés et la classe des composés codés par le génome. Une stratégie visant à cibler un groupe génétique biosynthétique codant une entité chimique d’intérêt doit être adoptée, et des extraits de culture d’une souche de type sauvage et/ou d’une souche hétérologue contenant le BGC peuvent être analysés pour générer des ions groupés basés sur des similitudes à l’aide duPNBS 26,31. Par conséquent, il est possible d’identifier de nouvelles molécules qui s’associent au BGC ciblé et ne sont pas disponibles dans la base de données (principalement des analogues inconnus, parfois produits en bas de la vie). Il est pertinent de considérer que les utilisateurs peuvent contribuer à ces plates-formes et que la disponibilité des données bioinformatiques et MS/MS augmente rapidement, conduisant à un développement constant et la mise à niveau d’outils et d’algorithmes informatiques efficaces pour guider les connexions efficaces d’extraits complexes avec des molécules.
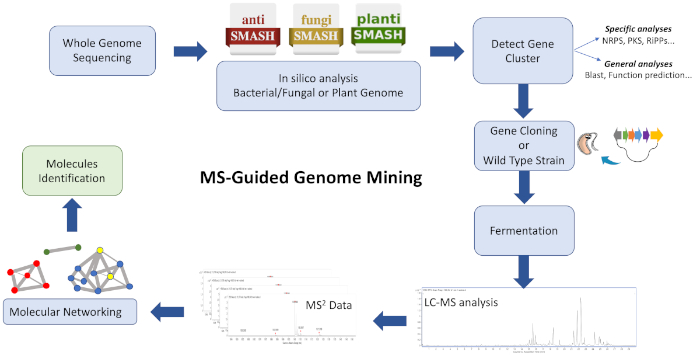
Figure 1 : Aperçu de l’ensemble du flux de travail. On y voit une illustration des étapes bioinformatiques, clonage et de réseautage moléculaire impliquées dans l’approche décrite d’extraction du génome guidée par ms pour identifier de nouveaux métabolites. S’il vous plaît cliquez ici pour voir une version plus grande de ce chiffre.
Ce protocole décrit un flux de travail rapide et efficace pour combiner l’extraction du génome et le réseautage moléculaire comme point de départ pour le pipeline naturel de découverte de produits. Bien que de nombreuses applications soient capables de visualiser la composition et la dataabilité des molécules détectables par la SP dans un réseau, plusieurs sont adoptées ici pour visualiser des molécules groupées structurellement similaires. En utilisant cette stratégie, de nouveaux produits de cyclodepsipeptide observés dans les extraits métaboliques de Streptomyces sp. CBMAI 2042 sont identifiés avec succès. Guidé par l’extraction du génome, l’ensemble du codage de faisceau de gènes biosynthétique pour les valinomycines est reconnu et cloné dans la souche productrice Streptomyces coelicolor M1146. Enfin, à la suite d’un réseau moléculaire basé sur le modèle de SP, les molécules détectées par LAS sont corrélées avec les BGC responsables de leur biogenèse32.
