Le indagini sul metabolismo secondario spesso consistono nello screening di estratti grezzi per specifiche attività biologiche seguite da purificazione, identificazione e caratterizzazione dei costituenti appartenenti a frazioni attive. Questo processo si è dimostrato efficiente, promuovendo l’isolamento di diverse entità chimiche. Tuttavia, al giorno d’oggi questo è visto come irrealizzabile, principalmente a causa degli alti tassi di riscoperta. Come l’industria farmaceutica rivoluzionato senza conoscenza dei ruoli e le funzioni di metaboliti specializzati, la loro identificazione è stata effettuata in condizioni di laboratorio che non rappresentavano con precisione la natura1. Oggi, c’è una migliore comprensione delle influenze di segnalazione naturale, secrezione, e la presenza della maggior parte degli obiettivi a concentrazioni non rilevabili basse. Inoltre, la regolamentazione del processo aiuterà la comunità accademica e l’industria farmaceutica a trarre vantaggio da queste conoscenze. Ne beneficeranno anche la ricerca che coinvolgerà l’isolamento diretto dei metaboliti legati ai cluster genici biosintetici silenziosi (BCC)2.
In questo contesto, i progressi nel sequenziamento genomico hanno rinnovato l’interesse per i metaboliti dei microrganismi di screening. Questo perché l’analisi delle informazioni genomiche degli ammassi biosintetici scoperti può rivelare geni che codificano nuovi composti non osservati o prodotti in condizioni di laboratorio. Molti progetti o correnti d’aria microbici dell’intero genoma sono oggi disponibili, e il numero è in crescita ogni anno, fornendo enormi prospettive per scoprire nuove molecole bioattive attraverso l’estrazione del genoma3,4.
L’Atlante dei cluster di geni biosintetici è la più grande collezione di cluster genici estratti automaticamente come componente della piattaforma integrata dei genomi microbici del Joint Genome Institute (JGI IMG-ABC)2. Più recentemente, la Minimum Information for Biosynthetic Gene Clusters (MIBiG) Standardization Initiative ha promosso la riannotazione manuale dei BMC, fornendo un set di dati di riferimento altamente curato5. Al giorno d’oggi, sono disponibili molti strumenti per consentire l’estrazione computazionale dei dati genetici e la loro connessione ai metaboliti secondari noti. Sono state inoltre sviluppate diverse strategie per accedere a nuovi prodotti naturali bioattivi (ad esempio, espressione etetologa, cancellazione genica mirata, ricostituzione in vitro, sequenza genomica, screening guidato da isotopi [approccio genomitopico], manipolazione delle autorità di regolamentazione locali e globali, estrazione basata su target di resistenza, estrazione indipendente dalla cultura e, più recentemente, approccio al codiceMS 2,6,7,8,9, 10,11,12,13,14,15).
L’estrazione del genoma come strategia singolare richiede sforzi per annotare un singolo o un piccolo gruppo di molecole; pertanto, permangono lacune nel processo in cui i nuovi composti sono prioritari per l’isolamento e la chiarificazione della struttura. In linea di principio, questi approcci si rivolgono a un solo percorso biosintetico per esperimento, con conseguente rallentamento del tasso di scoperta. In questo senso, l’utilizzo di GM insieme a un approccio di rete molecolare rappresenta un importante progresso per la ricerca sui prodotti naturali14,15.
La versatilità, la precisione e l’elevata sensibilità della spettrometria cromatografica-massa liquida (LC-MS) lo rendono un buon metodo per l’identificazione composta. Attualmente, diverse piattaforme hanno investito algoritmi e suite software per metabolomica non mirata16,17,18,19,20.20 Il nucleo di questi programmi include il rilevamento delle funzionalità (picco di raccolta)21 e l’allineamento di picco, che consente la corrispondenza di funzionalità identiche in un batch di campioni e la ricerca di modelli. Gli algoritmi basati su modelli MS22,,23 confrontano i modelli di frammentazione caratteristici e corrispondono alle somiglianze ms2 generando famiglie molecolari che condividono caratteristiche strutturali. Queste caratteristiche possono quindi essere evidenziate e raggruppate, conferendo la capacità di scoprire rapidamente molecole note e sconosciute da un complesso estratto biologico in tandem MS2,24,25. Pertanto, la SM in tandem è un metodo versatile per ottenere informazioni strutturali su diversi chemiotipi contenuti contemporaneamente in una grande quantità di dati.
L’algoritmo Global Natural Products Social Molecular Networking (GNPS)26 utilizza l’intensità degli ioni di frammento normalizzati per costruire vettori multidimensionali, in cui le somiglianze vengono confrontate utilizzando una funzione coseno. La relazione tra i diversi ioni padre viene tracciata in una rappresentazione del diagramma, in cui ogni frammentazione viene visualizzata come nodo (cerchi) e la correlazione di ogni nodo è definita da uno spigolo (linee). La visualizzazione globale delle molecole provenienti da un’unica fonte è definita come una rete molecolare. Molecole strutturalmente divergenti che si frammentano in modo univoco formeranno il proprio ammasso o costellazione specifica, mentre le molecole correlate si raggruppano. I chemiotipi di clustering consentono l’ipotetica connessione di caratteristiche strutturali simili alle loro origini biosintetiche.
La combinazione di approcci chemiotipo-genotipo e genotipo è potente quando si creano collegamenti bioinformatici tra BCC e i loro piccoli prodotti molecolari27. Pertanto, l’estrazione del genoma guidata dalla MS è un metodo rapido e una strategia a basso consumo di materiali e aiuta a colmare gli ioni dei genitori e le vie biosintetiche rivelate dal WGS di uno o più ceppi in diverse condizioni metaboliche e ambientali.
Il flusso di lavoro di questo protocollo (Figura 1) consiste nell’inserire i dati WGS in una piattaforma di annotazione del cluster di geni biosintetici come antiSMASH28,29,30. Aiuta a stimare la varietà di composti e la classe di composti codificati dal genoma. Deve essere adottata una strategia per colpire un cluster di geni biosintetici che codifica un’entità chimica di interesse, e gli estratti di coltura da un ceppo di tipo selvaggio e/o ceppo eteboloso contenente il BGC possono essere analizzati per generare ioni raggruppati in base alle somiglianze utilizzando GNPS26,31. Di conseguenza, è possibile identificare nuove molecole che si associano al BGC mirato e non sono disponibili nel database (principalmente analoghi sconosciuti, a volte prodotti in elementi bassi). È importante considerare che gli utenti possono contribuire a queste piattaforme e che la disponibilità di bioinformatica e dati MS/MS sta aumentando rapidamente, spingendo a uno sviluppo costante e l’aggiornamento di strumenti e algoritmi computazionali efficaci per guidare connessioni efficienti di estratti complessi con molecole.
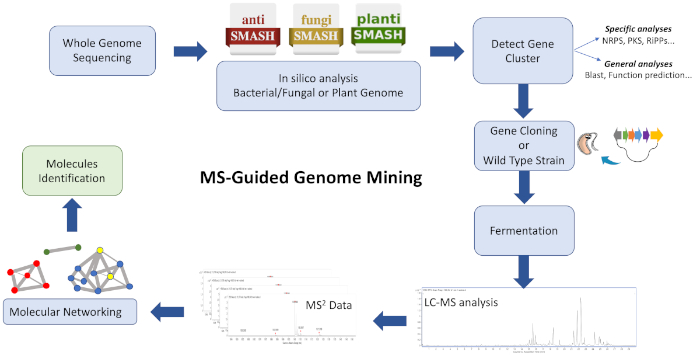
Figura 1: Panoramica dell’intero flusso di lavoro. È mostrato un’illustrazione delle fasi bioinformatiche, clonazione e networking molecolare coinvolte nell’approccio descritto nell’estrazione del genoma guidato dalla Ms per identificare nuovi metaboliti. Fare clic qui per visualizzare una versione più grande di questa figura.
Questo protocollo descrive un flusso di lavoro rapido ed efficiente per combinare l’estrazione del genoma e la rete molecolare come punto di partenza per la pipeline di scoperta naturale dei prodotti. Anche se molte applicazioni sono in grado di visualizzare la composizione e la relatedness delle molecole rilevabili dalla MS in una rete, diverse sono adottate qui per visualizzare molecole raggruppate strutturalmente simili. Utilizzando questa strategia, vengono identificati con successo nuovi prodotti ciclodepsipeptide osservati negli estratti metabolici di Streptomyces sp. CBMAI 2042. Guidato dall’estrazione del genoma, l’intera codifica del cluster genico biosintetico per le valiomiciche è riconosciuta e clonata nel ceppo produttore Streptomices coelicolor M1146. Infine, a seguito di una rete molecolare basata su modelli di SM, le molecole rilevate dalla SM sono correlate con i BMC responsabili della loro biogenesi32.
